Софтуер за наблюдение на пинг. Мониторинг на мрежата: как се уверяваме, че всички възли работят за големи компании
Здрав инструмент за наблюдение на пинг за автоматична проверка на връзката с мрежови хостове. Като прави редовни пингове, той следи мрежовите връзки и ви уведомява за открити възходи/падъци. EMCO Ping Monitor също предоставя информация за статистически данни за връзката, включително време за работа, прекъсвания, неуспешни пингове и др. Можете лесно да разширите функционалността и да конфигурирате EMCO Ping Monitor да изпълнява персонализирани команди или да стартира приложения, когато връзките са загубени или възстановени.
Какво е EMCO Ping Monitor?
EMCO Ping Monitor може да работи в 24/7 режим за проследяване на състоянията на връзката на един или няколко хоста. Приложението анализира ping отговорите, за да открие прекъсвания на връзката и да докладва статистика за връзката. Той може автоматично да открива прекъсвания на връзката и да показва балони на Windows Tray, да възпроизвежда звуци и да изпраща известия по имейл. Може също така да генерира отчети и да ги изпраща по имейл или да записва като PDF или HTML файлове.
Програмата ви позволява да получите информация за статусите на всички хостове, да проверите подробната статистика на избран хост и да сравните производителността на различни хостове. Програмата съхранява събраните пинг данни в базата данни, така че можете да проверите статистиката за избран период от време. Наличната информация включва мин./макс./ср. време за пинг, отклонение на пинга, списък с прекъсвания на връзката и др. Тази информация може да бъде представена като мрежови данни и диаграми.
EMCO Ping Monitor: Как работи?
EMCO Ping Monitor може да се използва за извършване на наблюдение на пинг само на няколко хоста или хиляди хостове. Всички хостове се наблюдават в реално време от специални работни нишки, така че можете да получавате статистически данни в реално време и промени в състоянието на връзката за известия за всеки хост. Програмата няма специални изисквания за хардуер - можете да наблюдавате няколко хиляди хоста на типичен модерен компютър.
Програмата използва пингове за откриване на прекъсвания на връзката. Ако няколко пинга са неуспешни в необработен вид - той съобщава за прекъсване и ви уведомява за проблема. Когато връзката е установена и пинговете започват да преминават обаче - програмата открива края на прекъсването и ви уведомява за това. Можете да персонализирате условията за откриване на прекъсване и възстановяване, както и известия, използвани от програмата.
Сравнете характеристиките и изберете изданието
Програмата се предлага в три издания с различния набор от функции.
Сравнете издания
Безплатното издание позволява извършване на пинг мониторинг на до 5 хоста. Не позволява никаква конкретна конфигурация за хостове. Той работи като програма за Windows, така че наблюдението се спира, ако затворите потребителския интерфейс или излезете от Windows.
Безплатно за лична и търговска употреба
Професионално издание
Професионалното издание позволява наблюдение на до 250 хоста едновременно. Всеки хост може да има персонализирана конфигурация, като например известяване на получатели на имейл или персонализирани действия, които да бъдат изпълнени при загуба на връзка и събития за възстановяване. Той работи като услуга на Windows, така че наблюдението продължава дори ако затворите потребителския интерфейс или излезете от Windows.
Enterprise Edition
Изданието Enterprise няма ограничения за броя на наблюдаваните хостове. На модерен компютър е възможно да се наблюдават над 2500 хоста в зависимост от хардуерната конфигурация.
Това издание включва всички налични функции и работи като клиент/сървър. Сървърът работи като услуга на Windows, за да осигури наблюдение на ping в 24/7 режим. Клиентът е програма за Windows, която може да се свърже със сървър, работещ на локален компютър или към отдалечен сървър през LAN или Интернет. Множество клиенти могат да се свързват към един и същ сървър и да работят едновременно.
Това издание включва също уеб отчети, които позволяват отдалечен преглед на статистиката за мониторинг на хоста в уеб браузър.
Основните характеристики на EMCO Ping Monitor
Мониторинг на пинг за няколко хоста
Приложението може да наблюдава едновременно множество хостове. Безплатното издание на приложението позволява наблюдение на до пет хоста; Професионалното издание няма ограничение за броя на наблюдаваните хостове. Мониторингът на всеки хост работи независимо от други хостове.Можете да наблюдавате десетки хиляди хостове от модерен компютър.
Откриване на прекъсвания на връзката
Приложението изпраща ICMP ping ехо заявки и анализира ping ехо отговорите, за да наблюдава състоянието на връзката в 24/7 режим. Ако предварително зададеният брой пингове не успее подред, приложението открива прекъсване на връзката и ви уведомява за проблема. Приложението проследява всички прекъсвания, така че можете да видите кога хостът е бил офлайн.
Анализ на качеството на връзката
Когато приложението пингува наблюдаван хост, то записва и обобщава данни за всеки пинг, така че можете да получите информация за минималното, максималното и средното време за реакция на пинг и отклонението на пинг отговора от средното за всеки отчетен период. Това ви позволява да оцените качеството на мрежовата връзка.
Гъвкави известия
Ако искате да получавате известия за изгубена връзка, възстановена връзка и други събития, открити от приложението, можете да конфигурирате приложението да изпраща известия по имейл, да възпроизвежда звуци и да показва балони на Windows Tray. Приложението може да изпраща едно известие от всякакъв вид или да повтаря известия няколко пъти.
Графики и отчети
Цялата статистическа информация, събрана от приложението, може да бъде представена визуално с диаграми. Можете да видите статистиката за пинга и времето за работа за един хост и да сравните производителността на множество хостове в диаграми. Приложението може автоматично да генерира отчети в различни формати на регулярна основа, за да представи статистиката на хоста.
Персонализирани действия
Можете да интегрирате приложението с външен софтуер, като изпълнявате външни скриптове или изпълними файлове, когато връзките са загубени или възстановени или в случай на други събития. Например, можете да конфигурирате приложението да изпълнява външен инструмент за команден ред, за да изпраща SMS известия за всякакви промени в статусите на хоста.
По външния вид на тази оптика, преминаваща през гората към колектора, можем да заключим, че инсталаторът не е спазил малко технологията. Монтажът на снимката също подсказва, че вероятно е моряк - морски възел.
Аз съм в екипа за здраве на физическата мрежа,с други думи, техническа поддръжка, която е отговорна за това, че светлините на рутерите мигат както трябва. Имаме под крилото си различни големи компании с инфраструктура в цялата страна. Ние не се катерим в техния бизнес, нашата задача е да гарантираме, че мрежата работи на физическо ниво и трафикът минава както трябва.
Общият смисъл на работата е постоянно анкетиране на възли, премахване на телеметрия, тестови пускания (например проверка на настройките за намиране на уязвимости), осигуряване на здраве, мониторинг на приложения, трафик. Понякога инвентаризации и други извращения.
Ще ви разкажа как е организирано и няколко истории от пътуванията.
Както обикновено се случва
Нашият екип седи в офис в Москва и взема мрежова телеметрия. Всъщност това са постоянни пингове на възли, както и получаване на мониторингови данни, ако хардуерът е интелигентен. Най-често срещаната ситуация е, че пингът не минава няколко пъти подред. В 80% от случаите за търговска верига, например, това се оказва прекъсване на тока, така че ние, виждайки тази картина, правим следното:- Първо се обаждаме на доставчика за злополуки
- След това - към електроцентралата за спирането
- След това се опитваме да установим връзка с някого в съоръжението (това не винаги е възможно, например в 2 часа сутринта)
- И накрая, ако горното не помогна за 5-10 минути, напускаме себе си или изпращаме „аватар“ - договорен инженер, който седи някъде в Ижевск или Владивосток, ако проблемът е там.
- Поддържаме постоянна връзка с "аватара" и го "водим" през инфраструктурата - имаме сензори и сервизни ръководства, той има клещи.
- Тогава инженерът ни изпраща доклад със снимка какво е било.
Диалогът понякога протича така:
- И така, връзката се губи между сгради номер 4 и 5. Проверете рутера в петата.
- Поръчка, включена. Няма връзка.
- Добре, върви по кабела към четвъртата сграда, там има още един възел.
-… Опа!
- Какво стана?
- Тук 4-та къща беше съборена.
- Какво??
- Прилагам снимка към репортажа. Не мога да възстановя къщата в SLA.

Но по-често все пак се оказва, че намирате прекъсване и възстановявате канала.
Приблизително 60% от пътуванията са „в млякото“, защото или захранването е прекъснато (от лопата, бригадир, натрапници), или доставчикът не знае за неговата повреда, или краткотраен проблем е отстранен преди монтажника пристига. Въпреки това, има моменти, когато разбираме за проблема преди потребителите и преди ИТ услугите на клиента и съобщаваме решението, преди те дори да осъзнаят, че нещо се е случило. Най-често такива ситуации се случват през нощта, когато активността в компаниите клиенти е ниска.
Кому е нужно и защо
По правило всяка голяма компания има собствен ИТ отдел, който ясно разбира спецификата и задачите. В средния и големия бизнес работата на "еникеевци" и мрежови инженери често се възлага на външни изпълнители. Просто е полезно и удобно. Например, един търговец на дребно има свои много готини ИТ хора, но те са далеч от подмяната на рутери и проследяване на кабели.Какво правим
- Работим по заявки - билети и панически обаждания.
- Правим профилактика.
- Ние следваме препоръките на доставчиците на хардуер, например относно условията за поддръжка.
- Свързваме се с наблюдението на клиента и премахваме данни от него, за да пътуваме в случай на инциденти.
Първият начин - прости проверки - е просто машина, която пингува всички възли в мрежата и се уверява, че отговарят правилно. Такава реализация не изисква никакви промени или минимални козметични промени в мрежата на клиента. Като правило, в много прост случай, ние инсталираме Zabbix директно на себе си в един от центровете за данни (за щастие имаме два от тях в офиса на CROC на Волочаевская). В по-сложен, например, ако използвате собствена защитена мрежа - към една от машините в центъра за данни на клиента:

Zabbix може да се използва по-сложен, например има агенти, които са инсталирани на * nix и win възли и показват мониторинг на системата, както и режим на външна проверка (с поддръжка на протокола SNMP). Независимо от това, ако бизнесът се нуждае от нещо подобно, тогава или вече има собствен мониторинг, или се избира по-функционално богато решение. Разбира се, това вече не е с отворен код и струва пари, но дори банален точен инвентар вече надминава разходите с около една трета.
Ние също така правим, но това е историята на колегите. Тук те изпратиха няколко екранни снимки на Infosim:


Аз съм оператор на аватар, така че ще ви разкажа повече за работата си.
Как изглежда един типичен инцидент?
Пред нас са екрани със следното общо състояние:
На този сайт Zabbix събира доста много информация за нас: номер на част, сериен номер, използване на процесора, описание на устройството, наличност на интерфейси и т.н. Цялата необходима информация е достъпна от този интерфейс.
Една обикновена случка обикновено започва с това, че един от каналите, водещи например към магазина на клиента (от който той има 200-300 броя в цялата страна) пада. Търговията на дребно вече е добре развита, не както преди седем години, така че касата ще продължи да работи - има два канала.
Вдигаме телефоните и правим поне три обаждания: до доставчика, централата и хората на място („Да, тук заредихме арматура, нечий кабел беше докоснат... А, твоя? Е, добре, че намерихме го”).
Като правило, без наблюдение, часове или дни биха минали преди ескалация - едни и същи резервни канали не винаги се проверяват. Веднага знаем и веднага си тръгваме. Ако има допълнителна информация освен пингове (например модел на бъги парче желязо), ние незабавно допълваме полевия инженер с необходимите части. По-нататък вече на място.
Второто най-често редовно обаждане е повредата на един от терминалите за потребителите, например DECT телефон или Wi-Fi рутер, който разпределя мрежата до офиса. Тук научаваме за проблема от наблюдението и почти веднага получаваме обаждане с подробности. Понякога обаждането не добавя нищо ново („Вдигам телефона, нещо не звъни“), понякога е много полезно („Изпуснахме го от масата“). Ясно е, че във втория случай това очевидно не е прекъсване на реда.
Оборудването в Москва се взема от нашите горещи резервни складове, имаме няколко вида от тях:

Клиентите обикновено имат собствени запаси от често неизправни компоненти - офис слушалки, захранвания, вентилатори и т.н. Ако трябва да доставите нещо, което не е на място, не до Москва, обикновено отиваме сами (защото монтаж). Например, имах нощно пътуване до Нижни Тагил.
Ако клиентът има собствен мониторинг, той може да качи данни при нас. Понякога внедряваме Zabbix в режим на запитване, само за да гарантираме прозрачност и SLA контрол (това също е безплатно за клиента). Не инсталираме допълнителни сензори (това се прави от колеги, които осигуряват непрекъснатост на производствените процеси), но можем да се свържем с тях, ако протоколите не са екзотични.
Като цяло, ние не докосваме инфраструктурата на клиента, ние просто я поддържаме такава, каквато е.
От опит мога да кажа, че последните десет клиента преминаха към външна поддръжка поради факта, че сме много предвидими по отношение на разходите. Ясно бюджетиране, добро управление на случаите, отчет за всяка заявка, SLA, отчети за оборудването, превантивна поддръжка. В идеалния случай, разбира се, ние сме за CIO на клиент като чистачите - идваме и го правим, всичко е чисто, не разсейваме.
Друго нещо, което си струва да се отбележи, е, че в някои големи компании инвентаризацията се превръща в истински проблем и понякога сме привлечени само да го изпълним. Освен това правим съхранението на конфигурации и тяхното управление, което е удобно за различни премествания и превръзки. Но, отново, в трудни случаи, това също не съм аз - имаме специален, който транспортира центрове за данни.
И още един важен момент: нашият отдел не се занимава с критична инфраструктура. Всичко в центровете за данни и всичко банково-застрахователно-оператор, плюс основните системи на дребно - това е X-екип. тези хора.
Повече практика
Много съвременни устройства са в състояние да дадат много сервизна информация. Например, мрежовите принтери са много лесни за наблюдение на нивото на тонера в касетата. Можете да разчитате на периода на подмяна предварително, плюс да имате 5-10% известие (ако офисът изведнъж започне да пише яростно не в стандартния график) - и незабавно да изпратите enikey, преди счетоводството да започне да се паникьосва.Много често ни се отнема годишната статистика, което се прави от същата система за наблюдение плюс ние. В случая със Zabbix това е просто планиране на разходите и разбиране какво се е объркало, а в случая с Infosim също е материал за изчисляване на мащабиране за една година, зареждане на администратори и всякакви други неща. В статистиката има разход на енергия - през последната година почти всички започнаха да го питат, явно за да разпръснат вътрешни разходи между отделите.
Понякога се получават истински героични спасения. Такива ситуации са много редки, но от това, което си спомням тази година, видяхме около 3 часа сутринта, че температурата се повиши до 55 градуса на cisco switch. В далечната сървърна стая имаше "глупави" климатици без наблюдение и те се отказаха. Веднага извикахме охладител (не наш) и извикахме дежурния администратор на клиента. Той пусна някои некритични услуги и запази сървърната стая от термичен удар, докато не пристигна човекът с мобилен климатик, а след това бяха оправени обикновените.
Polycom и друго скъпо оборудване за видеоконферентна връзка следят много добре нивото на зареждане на батерията преди конференции, което също е важно.
Всеки има нужда от наблюдение и диагностика. Като правило е дълъг и труден за изпълнение без опит: системите са или изключително прости и предварително конфигурирани, или с размерите на самолетоносач и с куп стандартни отчети. Заточването с файл за компанията, измислянето на изпълнението на задачите им за вътрешния ИТ отдел и показването на информацията, от която се нуждаят най-много, плюс поддържането на цялата история актуална е грабване, ако няма опит в внедряването. Когато работим със системи за наблюдение, ние избираме златната среда между безплатни и топ решения - като правило не най-популярните и "дебели" доставчици, но ясно решаващи проблема.
Веднъж имаше доста нетипично лечение. Клиентът трябваше да даде рутера на някои свои отделни подразделения и то точно според инвентара. Рутерът имаше модул с посочения сериен номер. Когато рутерът започна да се подготвя за пътя, се оказа, че този модул липсва. И никой не може да го намери. Проблемът леко се задълбочава от факта, че инженерът, който е работил с този бранш миналата година, вече е пенсионер и е заминал да живее при внуците си в друг град. Свързаха се с нас и поискаха да ги разгледаме. За щастие хардуерът даде отчети за серийни номера, а Infosim направи инвентаризация, така че намерихме този модул в инфраструктурата за няколко минути и описахме топологията. Беглецът е проследен по кабел - бил в друга сървърна стая в килер. Историята на движението показа, че той е стигнал до там след повреда на подобен модул.

Кадър от игрален филм за Хоттабич, точно описващ отношението на населението към камерите
Много инциденти с камери.Веднъж 3 камери се отказаха наведнъж. Прекъсване на кабела в една от секциите. Монтажникът духна нов в гофрирането, две от трите камери се издигнаха след поредица от шаманство. А третото не е така. Още повече, че изобщо не е ясно къде се намира. Вдигам видео потока - последните кадри точно преди падането - 4 сутринта, излизат трима мъже с шалове на лицата, нещо светло отдолу, камерата се тресе много, пада.
След като настроихме камерата, която трябва да се фокусира върху "зайците", които се катерят през оградата. Докато шофирахме, мислехме как да обозначим мястото, където трябва да се появи натрапникът. Не дойде по-удобно - за 15 минути, в които бяхме там, 30 души влязоха в обекта само в точката, от която се нуждаехме. Права маса.
Както вече дадох пример по-горе, историята за съборената сграда не е шега. След като връзката към оборудването изчезна. На място - няма павилион, където е минавала мед. Павилионът беше съборен, кабелът го нямаше. Видяхме, че рутерът е мъртъв. Инсталаторът пристигна, започна да търси - и разстоянието между възлите е няколко километра. В комплекта си има випнет тестер, стандартен - от един конектор звънна, от друг - отиде да търси. Обикновено проблемът се вижда веднага.

Проследяване на кабела: това е гофрирана оптика, продължение на историята от самия връх на публикацията за възела. Тук в крайна сметка, освен напълно невероятната инсталация, проблемът беше, че кабелът се беше отдалечил от монтажите. Тук се катерете всички и разхлабвайте метални конструкции. Приблизително петхилядният представител на пролетариата счупи оптиката.
В едно съоръжение всички възли бяха изключени около веднъж седмично.И в същото време. От доста време търсим модел. Инсталаторът намери следното:
- Проблемът възниква винаги при смяната на един и същ човек.
- Той се различава от другите по това, че носи много тежко палто.
- Зад закачалка за дрехи е монтирана автоматична машина.
- Някой пое капака на машината много отдавна, още в праисторически времена.
- Когато този другар идва в съоръжението, той закачва дрехите си, а тя изключва машините.
- Той веднага ги включва отново.
Оборудването беше изключено по едно и също време по едно и също време през нощта.Оказа се, че местни майстори се свързаха към захранването ни, извадиха удължител и забиха там чайник и електрическа печка. Когато тези устройства работят едновременно, целият павилион е нокаутиран.
В един от магазините на огромната ни страна цялата мрежа непрекъснато падаше със затварянето на смяната.Монтажникът видя, че цялата мощност е доведена до линията за осветление. Веднага след като горното осветление на залата (което консумира много енергия) се изключи в магазина, цялото мрежово оборудване се изключва.
Имаше случай, че портиерът прекъсна кабела с лопата.
Често виждаме просто мед, лежаща с разкъсана гофрировка. Веднъж, между две работилници, местни майстори просто препратиха кабел с усукана двойка без никаква защита.
Далеч от цивилизацията, служителите често се оплакват, че са изложени на „нашето“ оборудване.Таблата на някои отдалечени обекти може да са в същата стая като дежурния. Съответно на няколко пъти се натъкнахме на вредни баби, които неволно ги изключиха в началото на смяната.
Друг далечен град закачи моп на оптиката. Те счупиха гофрирането от стената, започнаха да го използват като крепежни елементи за оборудване.

В този случай явно има проблеми с храненето.
Какво може да направи "голямото" наблюдение
Ще говоря накратко за възможностите на по-сериозните системи, като използвам примера на инсталациите на Infosim. Има 4 решения, комбинирани в една платформа:- Управление на неизправности – контрол на откази и корелация на събития.
- Управление на производителността.
- Инвентаризация и автоматично откриване на топология.
- Управление на конфигурацията.
Отделно за инвентара. Модулът не само показва списъка, но и изгражда самата топология (поне в 95% от случаите се опитва и се оправя). Също така ви позволява да имате под ръка актуална база данни за използвано и неактивно ИТ оборудване (мрежа, сървърно оборудване и др.), за да сменяте остарялото оборудване навреме (EOS / EOL). Като цяло е удобно за големи фирми, но в малкия бизнес голяма част от това се прави на ръка.
Примери за отчети:
- Отчети по тип ОС, фърмуер, модели и производители на оборудване;
- Отчет за броя на свободните портове на всеки комутатор в мрежата / по избран производител / по модел / по подмрежа и др.;
- Отчет за новодобавени устройства за определен период;
- Предупреждение за нисък тонер на принтера;
- Оценка на пригодността на комуникационния канал за трафик, чувствителен към закъснения и загуби, активни и пасивни методи;
- Проследяване на качеството и наличността на комуникационните канали (SLA) - генериране на отчети за качеството на комуникационните канали, разбити по телеком оператори;
- Функционалността за контрол на неизправности и корелация на събития се осъществява чрез механизма за анализ на първопричините (без да е необходимо администраторите да пишат правила) и механизма на машината за алармени състояния. Анализът на първопричината е анализ на първопричината за авария, базиран на следните процедури: 1. автоматично откриване и локализиране на мястото на аварията; 2. намаляване на броя на аварийните събития до един ключ; 3. идентифициране на последствията от провала – кой и какво е засегнат от провала.

Stablenet - Embedded Agent (SNEA) - компютър, малко по-голям от кутия цигари.
Инсталирането се извършва в банкомати или специални мрежови сегменти, където се изисква тестване за достъпност. С тяхна помощ се извършва тестване на натоварване.
Мониторинг в облака
Друг инсталационен модел е SaaS в облака. Създаден за един глобален клиент (компания с непрекъснат производствен цикъл с география на разпространение от Европа до Сибир).Десетки съоръжения, включително фабрики и складове за готова продукция. Ако каналите им паднаха и поддръжката им беше извършена от чуждестранни офиси, тогава започнаха забавяния на доставката, което покрай вълната доведе до допълнителни загуби. Цялата работа беше извършена по заявка и беше отделено много време за разследване на инцидента.
Създадохме наблюдение специално за тях, след което го завършихме на редица сайтове според спецификата на тяхното маршрутизиране и хардуер. Всичко това беше направено в облака CROC. Те завършиха и изпълниха проекта много бързо.
Резултатът е:
- Поради частичното прехвърляне на управлението на мрежовата инфраструктура беше възможно да се оптимизира поне 50%. Недостъпност на оборудването, натоварване на канала, превишаване на параметрите, препоръчани от производителя: всичко това се фиксира в рамките на 5-10 минути, диагностицира и елиминира в рамките на един час.
- При получаване на услуга от облака, клиентът прехвърля капиталовите разходи за внедряване на своята система за наблюдение на мрежата в оперативни разходи срещу абонаментна такса за нашата услуга, от която може да се откаже по всяко време.
Предимството на облака е, че в нашето решение ние стоим сякаш над тяхната мрежа и можем да погледнем по-обективно на всичко, което се случва. По това време, ако бяхме вътре в мрежата, щяхме да виждаме картината само до възела на повреда и какво се случва зад нея, вече нямаше да знаем.
Няколко последни снимки
Това е "сутрешният пъзел":
И това е съкровището, което намерихме:

Ето какво имаше в сандъка:

И накрая, за най-смешното излизане. Веднъж отидох в търговски обект.
Там се случи следното: първо започна да капе от покрива върху окачения таван.Тогава в окачения таван се образува езеро, което ерозира и смачква една от плочките. В резултат всичко това бликна при електротехника. Тогава не знам какво точно се случи, но някъде в съседната стая имаше късо съединение и започна пожар. Първо заработиха праховите пожарогасители, а след това пристигнаха пожарникари и напълниха всичко с пяна. Пристигнах след тях за разглобяване. Трябва да кажа, че 2960 tsiska получи идеята след всичко това - успях да взема конфигурацията и да изпратя устройството за ремонт.
Още веднъж, по време на задействането на праховата система, Tsiskovsky 3745 в един буркан беше почти напълно пълен с прах. Всички интерфейси бяха пълни - 2 x 48 порта. Трябваше да се включи на място. Спомнихме си последния случай, решихме да се опитаме да премахнем конфигурациите „горещо“, разтърсихме го, почистихме го, доколкото можем. Включихме го - в началото устройството каза „pff“ и ни кихна с голяма струя прах. И тогава избухна и стана.
EMCO Ping монитор. Безплатен администраторски асистент
Ако вашата инфраструктура има до 5 хоста за виртуализация, можете да използвате безплатната версия.
Ping Monitor: Инструмент за наблюдение на състоянието на мрежовата връзка (безплатен за 5 хоста)
информация:
Надежден инструмент за наблюдение за автоматична проверка на връзката с мрежата от хостове чрез изпълнение на команда пинг.
Уики:
Ping е помощна програма за тестване на връзки в TCP/IP-базирани мрежи, както и общото име на самата заявка.
Помощната програма изпраща заявки (ICMP Echo-Request) на ICMP протокола до посочения хост и улавя входящи отговори (ICMP Echo-Reply). Времето между изпращане на заявка и получаване на отговор (RTT, от английското Round Trip Time) ви позволява да определите закъсненията при двупосочно пътуване (RTT) по маршрута и честотата на загуба на пакети, тоест косвено да определите задръстванията на канали за данни и междинни устройства.
Програмата за ping е един от основните диагностични инструменти в TCP/IP мрежите и е включена в доставката на всички съвременни мрежови операционни системи.
https://ru.wikipedia.org/wiki/Ping
Програмата, изпращайки редовни ICMP заявки, следи мрежовите връзки и ви уведомява за откритото възстановяване/спадане на канали. EMCO Ping Monitor предоставя статистически данни за връзката, включително време за работа, прекъсвания на услугата, неуспехи при пинг и др.


По външния вид на тази оптика, преминаваща през гората към колектора, можем да заключим, че инсталаторът не е спазил малко технологията. Монтажът на снимката също подсказва, че вероятно е моряк - морски възел.
Аз съм в екипа за здраве на физическата мрежа,с други думи, техническа поддръжка, която е отговорна за това, че светлините на рутерите мигат както трябва. Имаме под крилото си различни големи компании с инфраструктура в цялата страна. Ние не се катерим в техния бизнес, нашата задача е да гарантираме, че мрежата работи на физическо ниво и трафикът минава както трябва.
Общият смисъл на работата е постоянно анкетиране на възли, премахване на телеметрия, тестови пускания (например проверка на настройките за намиране на уязвимости), осигуряване на здраве, мониторинг на приложения, трафик. Понякога инвентаризации и други извращения.
Ще ви разкажа как е организирано и няколко истории от пътуванията.
Както обикновено се случва
Нашият екип седи в офис в Москва и взема мрежова телеметрия. Всъщност това са постоянни пингове на възли, както и получаване на мониторингови данни, ако хардуерът е интелигентен. Най-често срещаната ситуация е, че пингът не минава няколко пъти подред. В 80% от случаите за търговска верига, например, това се оказва прекъсване на тока, така че ние, виждайки тази картина, правим следното:- Първо се обаждаме на доставчика за злополуки
- След това - към електроцентралата за спирането
- След това се опитваме да установим връзка с някого в съоръжението (това не винаги е възможно, например в 2 часа сутринта)
- И накрая, ако горното не помогна за 5-10 минути, напускаме себе си или изпращаме „аватар“ - договорен инженер, който седи някъде в Ижевск или Владивосток, ако проблемът е там.
- Поддържаме постоянна връзка с "аватара" и го "водим" през инфраструктурата - имаме сензори и сервизни ръководства, той има клещи.
- Тогава инженерът ни изпраща доклад със снимка какво е било.
Диалогът понякога протича така:
- И така, връзката се губи между сгради номер 4 и 5. Проверете рутера в петата.
- Поръчка, включена. Няма връзка.
- Добре, върви по кабела към четвъртата сграда, там има още един възел.
-… Опа!
- Какво стана?
- Тук 4-та къща беше съборена.
- Какво??
- Прилагам снимка към репортажа. Не мога да възстановя къщата в SLA.
Но по-често все пак се оказва, че намирате прекъсване и възстановявате канала.
Приблизително 60% от пътуванията са „в млякото“, защото или захранването е прекъснато (от лопата, бригадир, натрапници), или доставчикът не знае за неговата повреда, или краткотраен проблем е отстранен преди монтажника пристига. Въпреки това, има моменти, когато разбираме за проблема преди потребителите и преди ИТ услугите на клиента и съобщаваме решението, преди те дори да осъзнаят, че нещо се е случило. Най-често такива ситуации се случват през нощта, когато активността в компаниите клиенти е ниска.
Кому е нужно и защо
По правило всяка голяма компания има собствен ИТ отдел, който ясно разбира спецификата и задачите. В средния и големия бизнес работата на "еникеевци" и мрежови инженери често се възлага на външни изпълнители. Просто е полезно и удобно. Например, един търговец на дребно има свои много готини ИТ хора, но те са далеч от подмяната на рутери и проследяване на кабели.Какво правим
- Работим по заявки - билети и панически обаждания.
- Правим профилактика.
- Ние следваме препоръките на доставчиците на хардуер, например относно условията за поддръжка.
- Свързваме се с наблюдението на клиента и премахваме данни от него, за да пътуваме в случай на инциденти.
Първият начин - прости проверки - е просто машина, която пингува всички възли в мрежата и се уверява, че отговарят правилно. Такава реализация не изисква никакви промени или минимални козметични промени в мрежата на клиента. Като правило, в много прост случай, ние инсталираме Zabbix директно на себе си в един от центровете за данни (за щастие имаме два от тях в офиса на CROC на Волочаевская). В по-сложен, например, ако използвате собствена защитена мрежа - към една от машините в центъра за данни на клиента:
Zabbix може да се използва по-сложен, например има агенти, които са инсталирани на * nix и win възли и показват мониторинг на системата, както и режим на външна проверка (с поддръжка на протокола SNMP). Независимо от това, ако бизнесът се нуждае от нещо подобно, тогава или вече има собствен мониторинг, или се избира по-функционално богато решение. Разбира се, това вече не е с отворен код и струва пари, но дори банален точен инвентар вече надминава разходите с около една трета.
Ние също така правим, но това е историята на колегите. Тук те изпратиха няколко екранни снимки на Infosim:
Аз съм оператор на аватар, така че ще ви разкажа повече за работата си.
Как изглежда един типичен инцидент?
Пред нас са екрани със следното общо състояние:
На този сайт Zabbix събира доста много информация за нас: номер на част, сериен номер, използване на процесора, описание на устройството, наличност на интерфейси и т.н. Цялата необходима информация е достъпна от този интерфейс.
Една обикновена случка обикновено започва с това, че един от каналите, водещи например към магазина на клиента (от който той има 200-300 броя в цялата страна) пада. Търговията на дребно вече е добре развита, не както преди седем години, така че касата ще продължи да работи - има два канала.
Вдигаме телефоните и правим поне три обаждания: до доставчика, централата и хората на място („Да, тук заредихме арматура, нечий кабел беше докоснат... А, твоя? Е, добре, че намерихме го”).
Като правило, без наблюдение, часове или дни биха минали преди ескалация - едни и същи резервни канали не винаги се проверяват. Веднага знаем и веднага си тръгваме. Ако има допълнителна информация освен пингове (например модел на бъги парче желязо), ние незабавно допълваме полевия инженер с необходимите части. По-нататък вече на място.
Второто най-често редовно обаждане е повредата на един от терминалите за потребителите, например DECT телефон или Wi-Fi рутер, който разпределя мрежата до офиса. Тук научаваме за проблема от наблюдението и почти веднага получаваме обаждане с подробности. Понякога обаждането не добавя нищо ново („Вдигам телефона, нещо не звъни“), понякога е много полезно („Изпуснахме го от масата“). Ясно е, че във втория случай това очевидно не е прекъсване на реда.
Оборудването в Москва се взема от нашите горещи резервни складове, имаме няколко вида от тях:
Клиентите обикновено имат собствени запаси от често неизправни компоненти - офис слушалки, захранвания, вентилатори и т.н. Ако трябва да доставите нещо, което не е на място, не до Москва, обикновено отиваме сами (защото монтаж). Например, имах нощно пътуване до Нижни Тагил.
Ако клиентът има собствен мониторинг, той може да качи данни при нас. Понякога внедряваме Zabbix в режим на запитване, само за да гарантираме прозрачност и SLA контрол (това също е безплатно за клиента). Не инсталираме допълнителни сензори (това се прави от колеги, които осигуряват непрекъснатост на производствените процеси), но можем да се свържем с тях, ако протоколите не са екзотични.
Като цяло, ние не докосваме инфраструктурата на клиента, ние просто я поддържаме такава, каквато е.
От опит мога да кажа, че последните десет клиента преминаха към външна поддръжка поради факта, че сме много предвидими по отношение на разходите. Ясно бюджетиране, добро управление на случаите, отчет за всяка заявка, SLA, отчети за оборудването, превантивна поддръжка. В идеалния случай, разбира се, ние сме за CIO на клиент като чистачите - идваме и го правим, всичко е чисто, не разсейваме.
Друго нещо, което си струва да се отбележи, е, че в някои големи компании инвентаризацията се превръща в истински проблем и понякога сме привлечени само да го изпълним. Освен това правим съхранението на конфигурации и тяхното управление, което е удобно за различни премествания и превръзки. Но, отново, в трудни случаи, това също не съм аз - имаме специален екип, който транспортира центрове за данни.
И още един важен момент: нашият отдел не се занимава с критична инфраструктура. Всичко в центровете за данни и всичко банково-застрахователно-оператор, плюс основните системи на дребно - това е X-екип. Ето ги момчетата.
Повече практика
Много съвременни устройства са в състояние да дадат много сервизна информация. Например, мрежовите принтери са много лесни за наблюдение на нивото на тонера в касетата. Можете да разчитате на периода на подмяна предварително, плюс да имате 5-10% известие (ако офисът изведнъж започне да пише яростно не в стандартния график) - и незабавно да изпратите enikey, преди счетоводството да започне да се паникьосва.Много често ни се отнема годишната статистика, което се прави от същата система за наблюдение плюс ние. В случая със Zabbix това е просто планиране на разходите и разбиране какво се е объркало, а в случая с Infosim също е материал за изчисляване на мащабиране за една година, зареждане на администратори и всякакви други неща. В статистиката има разход на енергия - през последната година почти всички започнаха да го питат, явно за да разпръснат вътрешни разходи между отделите.
Понякога се получават истински героични спасения. Такива ситуации са много редки, но от това, което си спомням тази година, видяхме около 3 часа сутринта, че температурата се повиши до 55 градуса на cisco switch. В далечната сървърна стая имаше "глупави" климатици без наблюдение и те се отказаха. Веднага извикахме охладител (не наш) и извикахме дежурния администратор на клиента. Той пусна някои некритични услуги и запази сървърната стая от термичен удар, докато не пристигна човекът с мобилен климатик, а след това бяха оправени обикновените.
Polycom и друго скъпо оборудване за видеоконферентна връзка следят много добре нивото на зареждане на батерията преди конференции, което също е важно.
Всеки има нужда от наблюдение и диагностика. Като правило е дълъг и труден за изпълнение без опит: системите са или изключително прости и предварително конфигурирани, или с размерите на самолетоносач и с куп стандартни отчети. Заточването с файл за компанията, измислянето на изпълнението на задачите им за вътрешния ИТ отдел и показването на информацията, от която се нуждаят най-много, плюс поддържането на цялата история актуална е грабване, ако няма опит в внедряването. Когато работим със системи за наблюдение, ние избираме златната среда между безплатни и топ решения - като правило не най-популярните и "дебели" доставчици, но ясно решаващи проблема.
Веднъж имаше доста нетипично лечение. Клиентът трябваше да даде рутера на някои свои отделни подразделения и то точно според инвентара. Рутерът имаше модул с посочения сериен номер. Когато рутерът започна да се подготвя за пътя, се оказа, че този модул липсва. И никой не може да го намери. Проблемът леко се задълбочава от факта, че инженерът, който е работил с този бранш миналата година, вече е пенсионер и е заминал да живее при внуците си в друг град. Свързаха се с нас и поискаха да ги разгледаме. За щастие хардуерът даде отчети за серийни номера, а Infosim направи инвентаризация, така че намерихме този модул в инфраструктурата за няколко минути и описахме топологията. Беглецът е проследен по кабел - бил в друга сървърна стая в килер. Историята на движението показа, че той е стигнал до там след повреда на подобен модул.
Кадър от игрален филм за Хоттабич, точно описващ отношението на населението към камерите
Много инциденти с камери.Веднъж 3 камери се отказаха наведнъж. Прекъсване на кабела в една от секциите. Монтажникът духна нов в гофрирането, две от трите камери се издигнаха след поредица от шаманство. А третото не е така. Още повече, че изобщо не е ясно къде се намира. Вдигам видео потока - последните кадри точно преди падането - 4 сутринта, излизат трима мъже с шалове на лицата, нещо светло отдолу, камерата се тресе много, пада.
След като настроихме камерата, която трябва да се фокусира върху "зайците", които се катерят през оградата. Докато шофирахме, мислехме как да обозначим мястото, където трябва да се появи натрапникът. Не дойде по-удобно - за 15 минути, в които бяхме там, 30 души влязоха в обекта само в точката, от която се нуждаехме. Права маса.
Както вече дадох пример по-горе, историята за съборената сграда не е шега. След като връзката към оборудването изчезна. На място - няма павилион, където е минавала мед. Павилионът беше съборен, кабелът го нямаше. Видяхме, че рутерът е мъртъв. Инсталаторът пристигна, започна да търси - и разстоянието между възлите е няколко километра. В комплекта си има випнет тестер, стандартен - от един конектор звънна, от друг - отиде да търси. Обикновено проблемът се вижда веднага.
Проследяване на кабела: това е гофрирана оптика, продължение на историята от самия връх на публикацията за възела. Тук в крайна сметка, освен напълно невероятната инсталация, проблемът беше, че кабелът се беше отдалечил от монтажите. Тук се катерете всички и разхлабвайте метални конструкции. Приблизително петхилядният представител на пролетариата счупи оптиката.
В едно съоръжение всички възли бяха изключени около веднъж седмично.И в същото време. От доста време търсим модел. Инсталаторът намери следното:
- Проблемът възниква винаги при смяната на един и същ човек.
- Той се различава от другите по това, че носи много тежко палто.
- Зад закачалка за дрехи е монтирана автоматична машина.
- Някой пое капака на машината много отдавна, още в праисторически времена.
- Когато този другар идва в съоръжението, той закачва дрехите си, а тя изключва машините.
- Той веднага ги включва отново.
Оборудването беше изключено по едно и също време по едно и също време през нощта.Оказа се, че местни майстори се свързаха към захранването ни, извадиха удължител и забиха там чайник и електрическа печка. Когато тези устройства работят едновременно, целият павилион е нокаутиран.
В един от магазините на огромната ни страна цялата мрежа непрекъснато падаше със затварянето на смяната.Монтажникът видя, че цялата мощност е доведена до линията за осветление. Веднага след като горното осветление на залата (което консумира много енергия) се изключи в магазина, цялото мрежово оборудване се изключва.
Имаше случай, че портиерът прекъсна кабела с лопата.
Често виждаме просто мед, лежаща с разкъсана гофрировка. Веднъж, между две работилници, местни майстори просто препратиха кабел с усукана двойка без никаква защита.
Далеч от цивилизацията, служителите често се оплакват, че са изложени на „нашето“ оборудване.Таблата на някои отдалечени обекти може да са в същата стая като дежурния. Съответно на няколко пъти се натъкнахме на вредни баби, които неволно ги изключиха в началото на смяната.
Друг далечен град закачи моп на оптиката. Те счупиха гофрирането от стената, започнаха да го използват като крепежни елементи за оборудване.
В този случай явно има проблеми с храненето.
Какво може да направи "голямото" наблюдение
Ще говоря накратко за възможностите на по-сериозните системи, като използвам примера на инсталациите на Infosim. Има 4 решения, комбинирани в една платформа:- Управление на неизправности – контрол на откази и корелация на събития.
- Управление на производителността.
- Инвентаризация и автоматично откриване на топология.
- Управление на конфигурацията.
Отделно за инвентара. Модулът не само показва списъка, но и изгражда самата топология (поне в 95% от случаите се опитва и се оправя). Също така ви позволява да имате под ръка актуална база данни за използвано и неактивно ИТ оборудване (мрежа, сървърно оборудване и др.), за да сменяте остарялото оборудване навреме (EOS / EOL). Като цяло е удобно за големи фирми, но в малкия бизнес голяма част от това се прави на ръка.
Примери за отчети:
- Отчети по тип ОС, фърмуер, модели и производители на оборудване;
- Отчет за броя на свободните портове на всеки комутатор в мрежата / по избран производител / по модел / по подмрежа и др.;
- Отчет за новодобавени устройства за определен период;
- Предупреждение за нисък тонер на принтера;
- Оценка на пригодността на комуникационния канал за трафик, чувствителен към закъснения и загуби, активни и пасивни методи;
- Проследяване на качеството и наличността на комуникационните канали (SLA) - генериране на отчети за качеството на комуникационните канали, разбити по телеком оператори;
- Функционалността за контрол на неизправности и корелация на събития се осъществява чрез механизма за анализ на първопричините (без да е необходимо администраторите да пишат правила) и механизма на машината за алармени състояния. Анализът на първопричината е анализ на първопричината за авария, базиран на следните процедури: 1. автоматично откриване и локализиране на мястото на аварията; 2. намаляване на броя на аварийните събития до един ключ; 3. идентифициране на последствията от провала – кой и какво е засегнат от провала.
Stablenet - Embedded Agent (SNEA) - компютър, малко по-голям от кутия цигари.
Инсталирането се извършва в банкомати или специални мрежови сегменти, където се изисква тестване за достъпност. С тяхна помощ се извършва тестване на натоварване.
Мониторинг в облака
Друг инсталационен модел е SaaS в облака. Създаден за един глобален клиент (компания с непрекъснат производствен цикъл с география на разпространение от Европа до Сибир).Десетки съоръжения, включително фабрики и складове за готова продукция. Ако каналите им паднаха и поддръжката им беше извършена от чуждестранни офиси, тогава започнаха забавяния на доставката, което покрай вълната доведе до допълнителни загуби. Цялата работа беше извършена по заявка и беше отделено много време за разследване на инцидента.
Създадохме наблюдение специално за тях, след което го завършихме на редица сайтове според спецификата на тяхното маршрутизиране и хардуер. Всичко това беше направено в облака CROC. Те завършиха и изпълниха проекта много бързо.
Резултатът е:
- Поради частичното прехвърляне на управлението на мрежовата инфраструктура беше възможно да се оптимизира поне 50%. Недостъпност на оборудването, натоварване на канала, превишаване на параметрите, препоръчани от производителя: всичко това се фиксира в рамките на 5-10 минути, диагностицира и елиминира в рамките на един час.
- При получаване на услуга от облака, клиентът прехвърля капиталовите разходи за внедряване на своята система за наблюдение на мрежата в оперативни разходи срещу абонаментна такса за нашата услуга, от която може да се откаже по всяко време.
Предимството на облака е, че в нашето решение ние стоим сякаш над тяхната мрежа и можем да погледнем по-обективно на всичко, което се случва. По това време, ако бяхме вътре в мрежата, щяхме да виждаме картината само до възела на повреда и какво се случва зад нея, вече нямаше да знаем.
Няколко последни снимки
Това е "сутрешният пъзел":
И това е съкровището, което намерихме:
Ето какво имаше в сандъка:
И накрая, за най-смешното излизане. Веднъж отидох в търговски обект.
Там се случи следното: първо започна да капе от покрива върху окачения таван.Тогава в окачения таван се образува езеро, което ерозира и смачква една от плочките. В резултат всичко това бликна при електротехника. Тогава не знам какво точно се случи, но някъде в съседната стая имаше късо съединение и започна пожар. Първо заработиха праховите пожарогасители, а след това пристигнаха пожарникари и напълниха всичко с пяна. Пристигнах след тях за разглобяване. Трябва да кажа, че 2960 tsiska получи идеята след всичко това - успях да взема конфигурацията и да изпратя устройството за ремонт.
Още веднъж, по време на задействането на праховата система, Tsiskovsky 3745 в един буркан беше почти напълно пълен с прах. Всички интерфейси бяха пълни - 2 x 48 порта. Трябваше да се включи на място. Спомнихме си последния случай, решихме да се опитаме да премахнем конфигурациите „горещо“, разтърсихме го, почистихме го, доколкото можем. Включихме го - в началото устройството каза „pff“ и ни кихна с голяма струя прах. И тогава избухна и стана.
ехо заявка
Заявката за ехо (ping) е диагностичен инструмент, използван, за да разберете дали конкретен хост е достъпен в IP мрежа. Заявката за ехо се прави с помощта на протокола ICMP (Internet Control Message Protocol). Този протокол се използва за изпращане на ехо заявка до проверявания хост. Хостът трябва да бъде конфигуриран да приема ICMP пакети.
Преглед
чрез ехо заявка
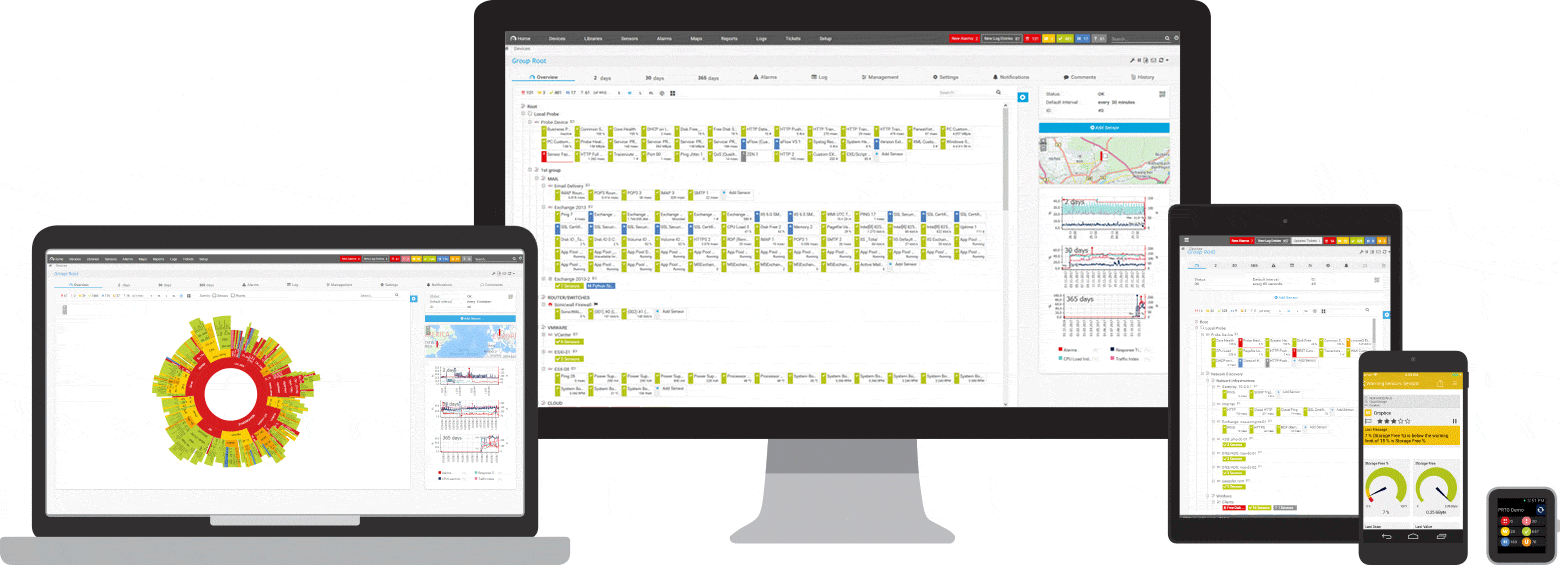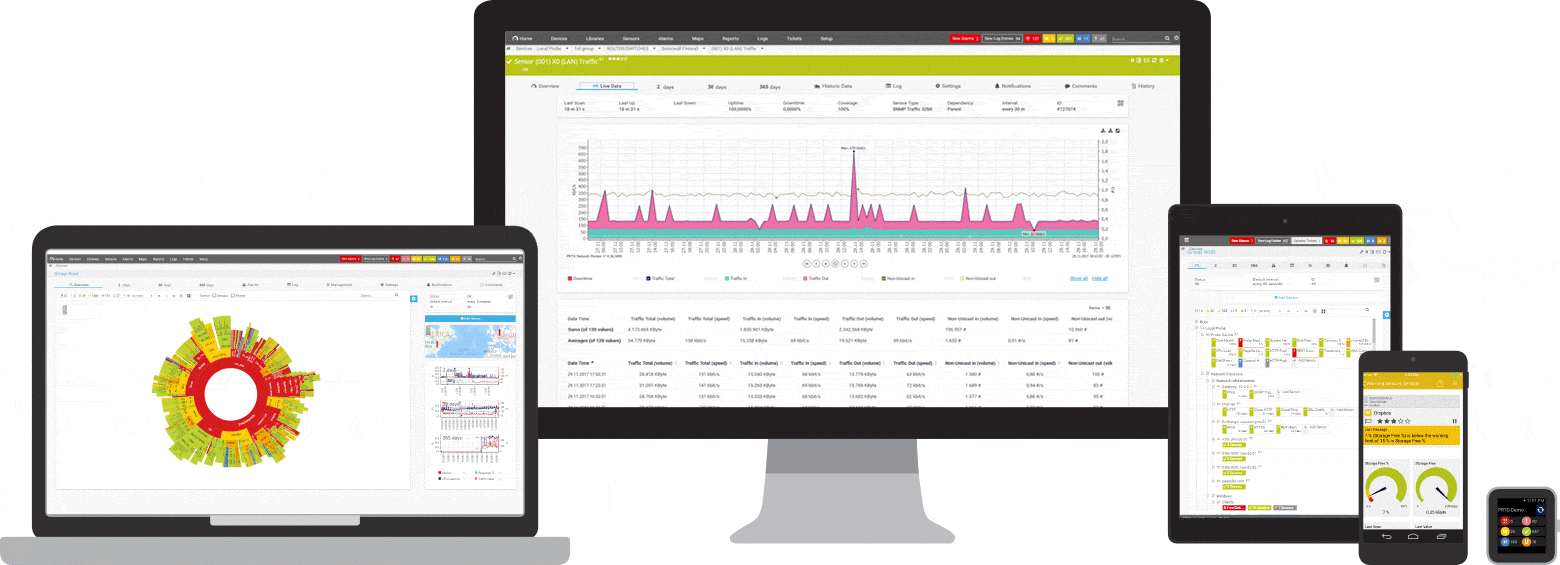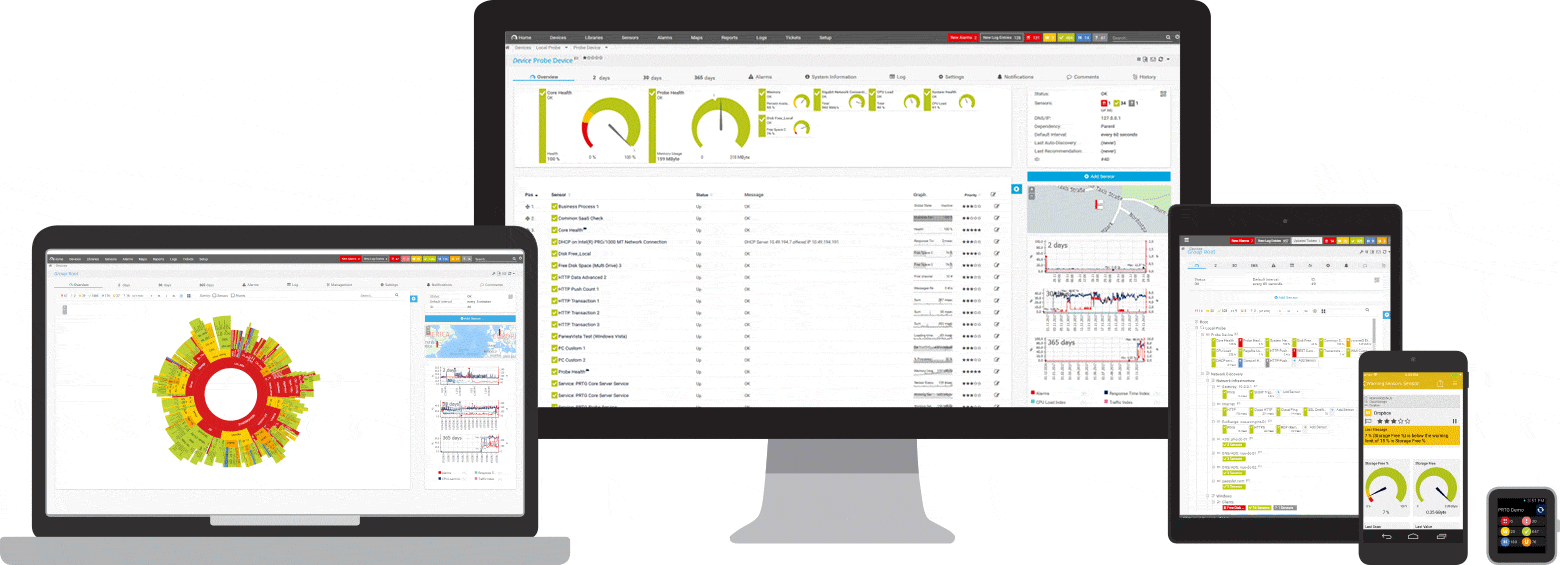
PRTG е инструмент за пинг и наблюдение на мрежата за Windows. Той е съвместим с всички основни Windows системи, включително Windows Server 2012 R2 и Windows 10.
PRTG е мощен инструмент за цялата мрежа. За сървъри, рутери, комутатори, ъптайм и облачни връзки, PRTG следи всичко, за да можете да премахнете неприятностите от администрирането. Сензорът за пинг, както и SNMP, NetFlow и сензорите за подслушване на пакети се използват за събиране на подробна информация за наличността на мрежата и работното натоварване.
PRTG има персонализирана вградена алармена система, която ви уведомява бързо за проблеми. Сензорът за пинг е конфигуриран като основен сензор за мрежови устройства. Ако този сензор се повреди, всички останали сензори на устройството се поставят в режим на заспиване. Това означава, че вместо поток от предупредителни съобщения, ще получите само едно известие.
По всяко време може да се покаже бърз преглед на таблото на PRTG. Веднага ще видите дали всичко е наред. Таблото за управление може да се персонализира, за да отговаря на вашите специфични нужди. Далеч от работното място, като например при работа в сървърна стая, достъпът до PRTG е възможен чрез приложение за смартфон и никога няма да пропуснете нито едно събитие.
Първоначалният мониторинг се конфигурира веднага по време на инсталацията. Това е възможно благодарение на функцията за автоматично откриване: PRTG пингува вашите лични IP адреси и автоматично създава сензори за наличните устройства. Когато отворите PRTG за първи път, можете веднага да проверите наличността на вашата мрежа.
Програмата PRTG има прозрачен модел на лицензиране. Можете да тествате PRTG безплатно. Сензорът за ехо заявка и функцията за аларма също са включени в безплатната версия и имат неограничен период на използване. Ако вашата компания или мрежа се нуждаят от повече функции, е лесно да надстроите лиценза си.
Екранни снимки
Кратко въведение в PRTG: Мониторинг на пинг



Вашите сензори за пинг в пълен изглед
- дори в движение
PRTG се инсталира за минути и е съвместим с повечето мобилни устройства.
PRTG контролира тези и много други производители и приложения вместо вас
Три PRTG сензора за наблюдение на пинг
Сензор
ехо заявки
от облака
Сензорът за пинг в облака използва PRTG Cloud за измерване на времето, необходимо за пинг на вашата мрежа от различни места по света. Този сензор ви позволява да видите наличността на вашата мрежа в Азия, Европа и Америка. По-специално, този показател е много важен за международните компании. .
Закупувайки софтуера PRTG, вие ще получите цялостна безплатна поддръжка. Нашата задача е да разрешим вашите проблеми възможно най-бързо! Специално за това, заедно с други материали, сме подготвили обучителни видеоклипове и изчерпателно ръководство. Ние се стремим да отговорим на всички билети за поддръжка в рамките на 24 часа (делнични дни). Ще намерите отговори на много въпроси в нашата база знания. Например, заявката за търсене "ping monitoring" връща 700 резултата. Няколко примера:
„Имам нужда от пинг сензор, който ще събира информация само за наличността на устройството, без да променя състоянието му. Възможно ли е?"
„Мога ли да създам обратен сензор за заявка за ехо?“

„С PRTG ни е много по-удобно, като знаем, че нашите системи се наблюдават непрекъснато.“
Маркус Пуке, мрежов администратор, клиника Шюхтерман (Германия)
- Пълна версия на PRTG за 30 дни
- След 30 дни - безплатна версия
- За разширена версия - търговски лиценз

| Софтуер за наблюдение на мрежата - версия 19.2.50.2842 (15 май 2019 г.) | |
|
Хостинг |
Налична е и облачна версия (PRTG в облака) |
езици |
Английски, немски, руски, испански, френски, португалски, холандски, японски и опростен китайски |
Цени |
Безплатни до 100 сензора (цени) |
Цялостно наблюдение |
Мрежови устройства, честотна лента, сървъри, приложения, виртуални среди, отдалечени системи, IoT и др. |
Поддържани доставчици и приложения |
Мониторинг на мрежа и пинг с PRTG: Три практически казуса
200 000 администратори по целия свят разчитат на програмата PRTG. Тези администратори може да идват от различни индустрии, но всички имат едно общо нещо – желанието да гарантират и подобрят достъпността и производителността на своите мрежи. Три случая на употреба:

летище Цюрих
Летище Цюрих е най-голямото летище в Швейцария, така че е особено важно всичките му електронни системи да функционират безпроблемно. За да направи това възможно, ИТ отделът внедри софтуера PRTG Network Monitor от Paessler AG. С над 4500 сензора, този инструмент гарантира, че проблемите ще бъдат незабавно открити и разрешени незабавно от ИТ екипа. В миналото ИТ отделът е използвал различни програми за наблюдение. Но в крайна сметка ръководството стигна до заключението, че софтуерът не е подходящ за специализиран мониторинг от персонала по експлоатация и поддръжка. Пример за употреба.

Университет Баухаус, Ваймар
ИТ системите на университета Баухаус във Ваймар се използват от 5000 студенти и 400 служители. В миналото за наблюдение на университетската мрежа се използваше изолирано решение, базирано на Nagios. Системата беше технически остаряла и не беше в състояние да отговори на нуждите на ИТ инфраструктурата на учебното заведение. Обновяването на инфраструктурата би било изключително скъпо. Вместо това университетът се обърна към нови решения за наблюдение на мрежата. ИТ ръководителите искаха цялостен софтуерен продукт, който да е лесен за използване, лесен за инсталиране и рентабилен. Затова избраха PRTG. Пример за употреба.

Комунални услуги на град Франкентал
Малко повече от 200 служители на комуналните услуги на град Франкентал отговарят за доставката на електричество, газ и вода на частни потребители и организации. Организацията, с всичките си сгради, също зависи от локално разпределена инфраструктура, която се състои от приблизително 80 сървъра и 200 свързани устройства. ИТ ръководителите на Frankenthal търсеха достъпен софтуер, който да отговори на техните специфични нужди. Първо, IT създаде безплатна пробна версия на PRTG. Обществените услуги на Frankenthal в момента използват около 1500 сензора, за да наблюдават, наред с други неща, обществени басейни. Пример за употреба.

Практически съвети. Кажи ми, Грег, имаш ли някакви препоръки за наблюдение на пингове?
„Pingback сензорите са може би най-важните елементи на наблюдението на мрежата. Те трябва да бъдат правилно конфигурирани, особено като се имат предвид вашите връзки. Ако, например, наблюдавате работата на виртуална машина, тогава е полезно да поставите пинг сензор във връзката с нейния хост. Ако възелът не успее, няма да получите известие за всяка свързана с него виртуална машина. В допълнение, сензорите за пинг могат да бъдат добри индикатори, че мрежовият път към хоста или интернет работи правилно, особено при сценарии с висока наличност или отказ.“
Грег Кемпион, системен администратор, PAESSLER AG