ping監視ソフトウェア。 ネットワーク監視:すべてのノードが大企業で機能することを確認する方法
ネットワークホストへの接続を自動チェックするための堅牢なping監視ツール。 定期的にpingを実行することで、ネットワーク接続を監視し、検出されたアップ/ダウンについて通知します。 EMCO Ping Monitorは、稼働時間、停止、pingの失敗などの接続統計情報も提供します。 機能を簡単に拡張し、接続が失われたり復元されたりしたときにカスタムコマンドを実行したり、アプリケーションを起動したりするようにEMCOPingMonitorを構成できます。
EMCO Ping Monitorとは何ですか?
EMCO Ping Monitorは、24時間年中無休のモードで動作して、1つまたは複数のホストの接続状態を追跡できます。 アプリケーションはping応答を分析して、接続の停止を検出し、接続統計を報告します。 接続の停止を自動的に検出し、Windowsトレイのバルーンを表示したり、サウンドを再生したり、電子メール通知を送信したりできます。 また、レポートを生成して電子メールで送信したり、PDFまたはHTMLファイルとして保存したりすることもできます。
このプログラムを使用すると、すべてのホストのステータスに関する情報を取得したり、選択したホストの詳細な統計を確認したり、さまざまなホストのパフォーマンスを比較したりできます。 プログラムは収集されたpingデータをデータベースに保存するため、選択した期間の統計を確認できます。 利用可能な情報には、最小/最大/平均ping時間、ping偏差、接続停止のリストなどが含まれます。 この情報は、グリッドデータおよびチャートとして表すことができます。
EMCO Pingモニター:どのように機能しますか?
EMCO Ping Monitorを使用して、わずか数台のホストまたは数千台のホストのping監視を実行できます。 すべてのホストは専用の作業スレッドによってリアルタイムで監視されるため、すべてのホストの接続状態の変化に関するリアルタイムの統計と通知を取得できます。 このプログラムには、ハードウェアに関する特別な要件はありません。一般的な最新のPCで数千のホストを監視できます。
プログラムはpingを使用して接続の停止を検出します。 いくつかのpingがrawで失敗した場合、停止を報告し、問題について通知します。 接続が確立され、pingが通過し始めると、プログラムは停止の終了を検出し、そのことを通知します。 停止をカスタマイズして、検出条件とプログラムで使用される通知を復元できます。
機能を比較してエディションを選択する
このプログラムは、機能の異なるセットを備えた3つのエディションで利用できます。
エディションの比較
Free Editionでは、最大5つのホストのping監視を実行できます。 ホストの特定の構成は許可されません。 Windowsプログラムとして実行されるため、UIを閉じるか、Windowsからログオフすると、監視が停止します。
個人および商用利用は無料
Professional Edition
Professionalエディションでは、最大250のホストを同時に監視できます。 すべてのホストは、電子メール受信者への通知や、接続が失われたイベントや復元イベントで実行されるカスタムアクションなどのカスタム構成を持つことができます。 Windowsサービスとして実行されるため、UIを閉じたり、Windowsからログオフしたりしても、監視は続行されます。
Enterprise Edition
Enterpriseエディションには、監視対象ホストの数に制限はありません。 最新のPCでは、ハードウェア構成に応じて2500以上のホストを監視できます。
このエディションには、利用可能なすべての機能が含まれており、クライアント/サーバーとして機能します。 サーバーはWindowsサービスとして機能し、24時間年中無休のモードでpingを監視します。 クライアントは、ローカルPCで実行されているサーバー、またはLANまたはインターネットを介してリモートサーバーに接続できるWindowsプログラムです。 複数のクライアントが同じサーバーに接続して同時に動作することができます。
このエディションには、Webブラウザでホスト監視統計をリモートで確認できるWebレポートも含まれています。
EMCOPingモニターの主な機能
マルチホストpingモニタリング
アプリケーションは、複数のホストを同時に監視できます。 アプリケーションの無料版では、最大5つのホストを監視できます。 Professionalエディションには、監視対象ホストの数に制限はありません。すべてのホストの監視は、他のホストから独立して機能します。最新のPCから数万のホストを監視できます。
接続停止の検出
アプリケーションはICMPpingエコー要求を送信し、pingエコー応答を分析して、24時間年中無休のモードで接続状態を監視します。 事前設定された数のpingが連続して失敗した場合、アプリケーションは接続の停止を検出し、問題を通知します。 アプリケーションはすべての停止を追跡するため、ホストがいつオフラインになったのかを確認できます。
接続品質分析
アプリケーションが監視対象ホストにpingを実行すると、すべてのpingに関するデータが保存および集約されるため、最小、最大、および平均のping応答時間と、任意のレポート期間の平均からのping応答の偏差に関する情報を取得できます。 これにより、ネットワーク接続の品質を見積もることができます。
柔軟な通知
接続が失われた、接続が復元された、およびアプリケーションによって検出されたその他のイベントに関する通知を受け取りたい場合は、電子メール通知を送信し、サウンドを再生し、Windowsトレイのバルーンを表示するようにアプリケーションを構成できます。 アプリケーションは、任意のタイプの単一の通知を送信したり、通知を複数回繰り返したりすることができます。
チャートとレポート
アプリケーションによって収集されたすべての統計情報は、チャートで視覚的に表すことができます。 単一のホストのpingと稼働時間の統計を確認し、グラフで複数のホストのパフォーマンスを比較できます。 アプリケーションは、ホスト統計を表すために、定期的にさまざまな形式のレポートを自動的に生成できます。
カスタムアクション
接続が失われたり復元されたりした場合、またはその他のイベントが発生した場合に外部スクリプトまたは実行可能ファイルを実行することにより、アプリケーションを外部ソフトウェアと統合できます。 たとえば、外部コマンドラインツールを実行して、ホストステータスの変更に関するSMS通知を送信するようにアプリケーションを構成できます。
この光学系の出現により、森を通り抜けてコレクターに到達することで、インストーラーはテクノロジーに少し従わなかったと結論付けることができます。 写真の台紙は、彼がおそらく船乗り、つまり海の結び目であることも示唆しています。
私はフィジカルネットワークヘルスチームに所属しています。つまり、ルータのライトが適切に点滅するようにするためのテクニカルサポートです。 私たちは、全国にインフラストラクチャを備えたさまざまな大企業を抱えています。 私たちは彼らのビジネスの内部に登ることはありません。私たちの仕事は、ネットワークが物理レベルで機能し、トラフィックが正常に通過することを確認することです。
作業の一般的な意味は、ノードの継続的なポーリング、テレメトリの削除、テストの実行(たとえば、脆弱性を見つけるための設定のチェック)、正常性の確保、アプリケーションの監視、トラフィックです。 時々在庫と他の倒錯。
それがどのように構成されているか、そして旅行からのいくつかの話についてお話します。
通常の場合のように
私たちのチームはモスクワのオフィスに座って、ネットワークテレメトリを利用しています。 実際には、これらはノードの一定のpingであり、ハードウェアがスマートである場合は監視データを取得します。 最も一般的な状況は、pingが連続して数回通過しないことです。 たとえば、小売チェーンの場合の80%で、これは停電であることが判明したため、この図を見て、次のことを行います。- まず、事故についてプロバイダーに電話します
- それから-シャットダウンについて発電所に
- 次に、施設の誰かとの接続を確立しようとします(これは、たとえば午前2時に常に可能であるとは限りません)
- そして最後に、上記が5〜10分で役に立たなかった場合、問題があれば、私たちは自分自身を離れるか、「アバター」を送ります。イジェフスクまたはウラジオストクのどこかに座っている契約エンジニアです。
- 私たちは常に「アバター」と連絡を取り、インフラストラクチャを通じて「アバター」を「リード」します。センサーとサービスマニュアルがあり、ペンチがあります。
- 次に、エンジニアはそれが何であったかについての写真付きのレポートを私たちに送信します。
対話は時々次のようになります:
-そのため、建物番号4と5の間の接続が失われます。5番目のルーターを確認してください。
-注文、含まれています。 接続はありません。
-わかりました。ケーブルに沿って4番目の建物に行きます。別のノードがあります。
-…おっパ!
- どうしたの?
-ここで4番目の家が取り壊されました。
- 何??
-レポートに写真を添付しています。 SLAで家を復元することはできません。

しかし、多くの場合、それでも休憩を見つけてチャネルを復元することが判明します。
旅行の約60%は「牛乳の中」です。これは、電源が(シャベル、職長、侵入者によって)中断されているか、プロバイダーがその障害について知らないか、設置者の前に短期間の問題が解消されているためです。到着。 ただし、ユーザーの前やお客様のITサービスの前に問題を発見し、何かが起こったことに気付く前に解決策を伝える場合があります。 ほとんどの場合、このような状況は、顧客企業の活動が少ない夜間に発生します。
誰がそれを必要とし、なぜ
原則として、大企業には独自のIT部門があり、詳細とタスクを明確に理解しています。 中規模および大規模のビジネスでは、「enikeevs」およびネットワークエンジニアの作業は外部委託されることがよくあります。 それはただ有益で便利です。 たとえば、ある小売業者には非常に優秀なIT担当者がいますが、ルーターを交換したりケーブルを追跡したりすることにはほど遠いです。私たちは何をしていますか
- チケットやパニックコールなどのリクエストに対応しています。
- 予防を行います。
- メンテナンスの条件など、ハードウェアベンダーの推奨事項に従います。
- 私たちは顧客の監視に接続し、事件が発生した場合に旅行するために顧客からデータを削除します。
最初の方法(単純なチェック)は、ネットワーク上のすべてのノードにpingを実行し、それらが正しく応答することを確認するマシンです。 このような実装では、顧客のネットワークにまったく変更を加える必要がないか、最小限の変更を加える必要があります。 原則として、非常に単純なケースでは、Zabbixをデータセンターの1つに直接インストールします(幸い、VolochaevskayaのCROCオフィスに2つあります)。 より複雑なものでは、たとえば、独自の安全なネットワークを使用している場合、顧客のデータセンター内のマシンの1つに次のようになります。

Zabbixはより複雑に使用できます。たとえば、エージェントが* nixノードとwinノードにインストールされ、システムモニタリングと、外部チェックモード(SNMPプロトコルのサポート付き)を表示します。 それでも、ビジネスに同様の何かが必要な場合は、すでに独自の監視機能を備えているか、より機能的に豊富なソリューションが選択されます。 もちろん、これはもはやオープンソースではなく、コストもかかりますが、平凡な正確な在庫でさえ、すでにコストを約3分の1上回っています。
私たちもこれを行いますが、これは同僚の話です。 ここで、Infosimのスクリーンショットをいくつか送信しました。


私はアバターオペレーターなので、私の仕事について詳しく説明します。
典型的な事件はどのように見えますか?
私たちの前には、次の一般的なステータスの画面があります。
このオブジェクトに関して、Zabbixは、バッチ番号、シリアル番号、CPU使用率、デバイスの説明、インターフェースの可用性など、非常に多くの情報を収集します。 必要なすべての情報は、このインターフェースから入手できます。
通常のインシデントは、通常、たとえば、顧客の店舗(全国に200〜300個ある店舗)につながるチャネルの1つが脱落するという事実から始まります。 小売業は7年前とは異なり、現在十分に発達しているため、興行収入は引き続き機能します。2つのチャネルがあります。
私たちは電話を取り、少なくとも3つの電話をかけます。プロバイダー、発電所、その場の人々に電話をかけます(「はい、ここにフィッティングをロードしました。誰かのケーブルに触れました...ああ、あなたの?我々はそれを見つけた")。
原則として、監視しないと、エスカレーションの前に数時間または数日が経過します。同じバックアップチャネルが常にチェックされるとは限りません。 私たちはすぐに知って、すぐに去ります。 ping以外の追加情報(たとえば、バグのある鉄片のモデル)がある場合は、必要な部品をフィールドエンジニアにすぐに完成させます。 さらにすでに実施されています。
2番目に頻繁な通常の通話は、ユーザーの端末の1つ、たとえば、ネットワークをオフィスに分散したDECT電話またはWi-Fiルーターの障害です。 ここでは、監視から問題について学び、ほとんどすぐに詳細を記載した電話を受けます。 呼び出しによって新しいものが追加されない場合(「電話を取りましたが、何かが鳴りません」)、非常に便利な場合があります(「テーブルからドロップしました」)。 2番目のケースでは、これは明らかに改行ではないことは明らかです。
モスクワの設備は私たちのホットリザーブ倉庫から取られています、私たちはそれらのいくつかのタイプを持っています:

顧客は通常、頻繁に故障するコンポーネント(オフィスの受話器、電源装置、ファンなど)を自社で在庫しています。 モスクワではなく、所定の場所にないものを配達する必要がある場合、私たちは通常、自分たちで行きます(設置のため)。 たとえば、私はニジニタギルへの夜の旅行をしました。
お客様が独自の監視を行っている場合は、データをアップロードできます。 透明性とSLA制御を確保するために、Zabbixをポーリングモードでデプロイする場合があります(これはお客様にとっても無料です)。 追加のセンサーはインストールしませんが(これは、生産プロセスの継続性を保証する同僚によって行われます)、プロトコルがエキゾチックでない場合はセンサーに接続できます。
通常、お客様のインフラストラクチャには触れず、そのままサポートします。
経験から、コストの面で非常に予測可能であるという事実のために、最後の10人の顧客が外部サポートに切り替えたと言えます。 明確な予算編成、適切なケース管理、各要求に関するレポート、SLA、機器レポート、予防保守。 もちろん、理想的には、私たちはクリーナーなどの顧客のCIOのためです。私たちはやって来て、すべてがきれいで、気を散らさないようにします。
注目に値するもう一つのことは、いくつかの大企業では、在庫が実際の問題になり、時にはそれを実行するためだけに私たちが惹かれることです。 さらに、構成の保存とその管理を行います。これは、さまざまな再配置や再接続に便利です。 しかし、繰り返しになりますが、困難なケースでは、これも私ではありません。データセンターを転送する特別なものがあります。
そしてもう1つの重要なポイントは、私たちの部門は重要なインフラストラクチャを扱っていないということです。 データセンター内のすべてと銀行保険事業者のすべてに加えて、小売コアシステム-これはXチームです。 こいつら。
もっと練習
最近の多くのデバイスは、多くのサービス情報を提供できます。 たとえば、ネットワークプリンタは、カートリッジ内のトナーのレベルを非常に簡単に監視できます。 事前に交換期間を頼りにすることができ、さらに5〜10%の通知を受け取ることができます(オフィスが標準のスケジュールではなく突然激しく入力し始めた場合)-そして経理部門がパニックに陥る前にすぐにenikeyを送信します。非常に多くの場合、年次統計は私たちから奪われます。これは、同じ監視システムと私たちによって行われます。 Zabbixの場合、これは単純なコスト計画と何がどこに行ったかを理解することであり、Infosimの場合は、1年間のスケーリングを計算したり、管理者をロードしたりするための資料でもあります。 統計にはエネルギー消費があります。昨年、ほとんどの人が彼に尋ね始めました。これは明らかに、部門間で内部コストを分散させるためです。
時には本当の英雄的な救助が得られます。 このような状況は非常にまれですが、今年のことを思い出すと、午前3時頃にCiscoスイッチで気温が55度に上昇しました。 遠くのサーバールームには、監視のない「ばかげた」エアコンがあり、故障しました。 私たちはすぐに(私たちではなく)冷却エンジニアに電話し、当直の顧客の管理者に電話しました。 彼はいくつかの重要ではないサービスを出し、男がモバイルエアコンを持って到着するまでサーバールームをサーマルショットダウンから守り、その後通常のエアコンを修理しました。
ポリコムやその他の高価なビデオ会議機器は、会議の前にバッテリーの充電レベルを非常によく監視します。これも重要です。
誰もが監視と診断を必要としています。 原則として、経験なしに実装することは長く困難です。システムは非常に単純で事前構成されているか、空母のサイズであり、多数の標準レポートがあります。 会社のファイルを研ぎ澄まし、社内IT部門のタスクの実装を考案し、最も必要な情報を表示し、さらに、実装の経験がない場合は、履歴全体を最新の状態に保つことは簡単です。 監視システムを使用する場合、無料ソリューションとトップソリューションの間の中庸を選択します。原則として、最も人気のある「厚い」ベンダーではありませんが、問題を明確に解決します。
かつてはかなり非定型の治療がありました。 顧客は、在庫に応じて、ルーターをいくつかの別々の部門に渡す必要がありました。 ルータには、指定されたシリアル番号のモジュールがありました。 ルーターが道路の準備を始めたとき、このモジュールが欠落していることが判明しました。 そして、誰もそれを見つけることができません。 昨年この支店で働いていたエンジニアがすでに引退しており、孫と別の都市に住んでいるという事実によって、問題は少し悪化しています。 彼らは私たちに連絡して、見るように頼みました。 幸い、ハードウェアがシリアル番号に関するレポートを提供し、Infosimがインベントリを作成したため、インフラストラクチャでこのモジュールを数分で見つけて、トポロジについて説明しました。 逃亡者はケーブルで追跡されました-彼はクローゼットの別のサーバールームにいました。 運動の歴史は、彼が同様のモジュールの失敗の後にそこに着いたことを示しました。

Hottabychに関する長編映画のフレームで、カメラに対する住民の態度を正確に説明しています
たくさんのカメラ事件。一度に3台のカメラが故障しました。 セクションの1つでケーブルが断線しました。 インストーラーは新しいものを波形に吹き込みました。3つの部屋のうちの2つは、一連のシャーマニズムの後に上昇しました。 そして3番目はそうではありません。 さらに、彼女がどこにいるのかはまったくはっきりしていません。 私はビデオストリームを上げます-秋の直前の最後のフレーム-4朝、顔にスカーフを着た3人の男性が現れ、下に何か明るいものがあり、カメラが大きく揺れ、落下します。
カメラをセットアップしたら、フェンスを越えて登る「うさぎ」に焦点を合わせる必要があります。 運転中、侵入者が現れる場所をどのように指定するかを考えました。 便利ではありませんでした。私たちがそこにいた15分間で、30人が必要な場所にのみオブジェクトを入力しました。 まっすぐなテーブル。
すでに上記の例を挙げたように、取り壊された建物についての話は冗談ではありません。 機器へのリンクが消えたら。 所定の場所-銅が通過したパビリオンはありません。 パビリオンは取り壊され、ケーブルはなくなりました。 ルーターが停止していることがわかりました。 インストーラーが到着し、探し始めました-ノード間の距離は数キロです。 彼のセットにはVipnetテスターがあり、標準(1つのコネクタから鳴り、別のコネクタから鳴りました)を探しに行きました。 通常、問題はすぐにわかります。

ケーブルの追跡:これは波形の光学部品であり、結び目についての投稿の最上部からの話の続きです。 ここで、結局のところ、絶対に驚くべきインストールに加えて、問題はケーブルがマウントから離れて移動したことでした。 ここですべてを登り、雑多になり、金属構造を緩めます。 プロレタリアートの約5000人目の代表者が光学系を壊しました。
ある施設では、すべてのノードが週に1回程度オフにされていました。そして同時に。 私たちはかなり前からパターンを探していました。 インストーラーは次を検出しました。
- 問題は常に同じ人のシフトで発生します。
- 彼は非常に重いコートを着ているという点で他の人とは異なります。
- ハンガーの後ろに自動機が取り付けられています。
- 先史時代に、誰かがずっと前に機械のカバーを取りました。
- この同志が施設に来ると、彼は服を脱ぎ、彼女は機械の電源を切ります。
- 彼はすぐにそれらをオンに戻します。
夜間に同時に機器の電源を切りました。地元の職人が私たちの電源に接続し、延長コードを取り出して、そこにやかんと電気ストーブを突き刺したことがわかりました。 これらのデバイスが同時に動作すると、パビリオン全体がノックアウトされます。
私たちの広大な国の店舗の1つでは、シフトの終了に伴い、ネットワーク全体が絶えず低下していました。設置者は、すべての電力が照明ラインに供給されていることを確認しました。 店舗内で(エネルギーを大量に消費する)ホールの天井照明がオフになるとすぐに、すべてのネットワーク機器がオフになります。
管理人がシャベルでケーブルを遮った場合がありました。
多くの場合、銅が引き裂かれた波形で横たわっているのを目にします。 かつて、2つのワークショップの間に、地元の職人が保護なしでツイストペアケーブルを転送しただけでした。
文明から離れて、従業員はしばしば彼らが「私たちの」機器にさらされていると不平を言います。一部の遠隔地の配電盤は、当直者と同じ部屋にある場合があります。 したがって、私たちは数回、シフトの開始時にフックまたは詐欺師によって彼らをオフにした有害な祖母に出くわしました。
別の遠い都市 光学系にモップをかけた。 彼らは壁から波形を壊し、それを機器の留め具として使い始めました。

この場合、明らかに栄養に問題があります。
「大きな」監視でできること
Infosimのインストール例を使用して、より深刻なシステムの機能について簡単に説明します。1つのプラットフォームに統合された4つのソリューションがあります。- 障害管理-障害制御とイベント相関。
- パフォーマンス管理。
- インベントリと自動トポロジ検出。
- 構成管理。
別途、在庫について。 モジュールはリストを表示するだけでなく、トポロジ自体も構築します(少なくとも、95%の場合、モジュールはそれを正しく実行しようとします)。 また、使用済みおよびアイドル状態のIT機器(ネットワーク、サーバー機器など)の最新のデータベースを手元に用意して、古い機器(EOS / EOL)を時間どおりに交換することもできます。 一般的に、大企業にとっては便利ですが、中小企業では、これの多くは手作業で行われます。
レポートの例:
- OSの種類、ファームウェア、モデル、機器メーカー別のレポート。
- ネットワーク内の各スイッチの空きポートの数/選択したメーカー別/モデル別/サブネット別などを報告します。
- 指定された期間に新しく追加されたデバイスについてレポートします。
- プリンタのトナー残量低下の警告。
- 遅延と損失に敏感なトラフィック、アクティブおよびパッシブ方式に対する通信チャネルの適合性の評価。
- 通信チャネル(SLA)の品質と可用性の追跡-通信事業者ごとに分類された、通信チャネルの品質に関するレポートの生成。
- 障害制御およびイベント相関機能は、根本原因分析メカニズム(管理者がルールを作成する必要なし)およびAlarmStatesMachineメカニズムを介して実装されます。 根本原因分析は、次の手順に基づいた事故の根本原因の分析です。1.障害サイトの自動検出と特定。 2.緊急事態の数を1つのキーに減らします。 3.障害の結果を特定する-障害によって誰が、何が影響を受けたか。

Stablenet-Embedded Agent(SNEA)-タバコのパックより少し大きいコンピューター。
インストールは、ATM、またはアクセシビリティテストが必要な専用ネットワークセグメントで実行されます。 彼らの助けを借りて、負荷テストが実行されます。
クラウドモニタリング
もう1つのインストールモデルは、クラウドでのSaaSです。 1人のグローバル顧客(ヨーロッパからシベリアへの流通地域を持つ継続的な生産サイクルを持つ会社)のために作られました。完成品の工場や倉庫など、数十の施設。 彼らのチャネルが落ち、彼らのサポートが外国のオフィスから実行された場合、出荷の遅延が始まり、波に沿って、さらなる損失につながりました。 すべての作業はリクエストに応じて行われ、インシデントの調査に多くの時間が費やされました。
私たちは彼らのために特別に監視を設定し、ルーティングとハードウェアの詳細に応じて多くのサイトで監視を終了しました。 これはすべてCROCクラウドで行われました。 彼らはプロジェクトを非常に迅速に完了し、実施しました。
結果は次のとおりです。
- ネットワークインフラストラクチャの管理が部分的に移行されたため、少なくとも50%を最適化することができました。 機器へのアクセス不能、チャネル負荷、製造元が推奨するパラメータを超える:これらはすべて5〜10分以内に修正され、1時間以内に診断および排除されます。
- クラウドからサービスを受けると、お客様はネットワーク監視システムを導入するための資本コストを、いつでも免除できるサービスのサブスクリプション料金の運用コストに振り替えます。
クラウドの利点は、私たちの決定において、いわば彼らのネットワークの上に立って、より客観的に起こるすべてを見ることができるということです。 そのとき、ネットワーク内にいると、障害ノードまでしか画像が表示されず、その背後で何が起こっているのかがわかりません。
最後の写真のカップル
これは「朝のパズル」です。
そして、これは私たちが見つけた宝物です:

これは胸にあったものです:

そして最後に、おかしな外出について。 私はかつて小売施設に行きました。
そこでは次のことが起こりました。最初に、それは屋根から仮天井に滴り始めました。その後、仮天井に湖が形成され、タイルの1つが浸食されて押しつぶされました。 その結果、これらすべてが電気技師に噴出しました。 何が起こったのか正確にはわかりませんが、隣の部屋のどこかで短絡が発生し、火災が発生しました。 最初に、粉末消火器が機能し、次に消防士が到着し、すべてを泡で満たしました。 分解のために彼らの後に到着しました。 私はtsiska2960がこのすべての直後にそれを手に入れたと言わなければなりません-私は設定を拾い上げて、修理のためにデバイスを送ることができました。
もう一度、粉末システムのトリガー中に、1つの缶のTsiskovsky3745がほぼ完全に粉末で満たされました。 すべてのインターフェイスがいっぱいでした-2x48ポート。 それはその場で含まれなければなりませんでした。 私たちは最後のケースを思い出し、構成を「ホット」に削除して、それを振り払い、可能な限りクリーンアップすることにしました。 私たちはそれをオンにしました-最初にデバイスは「pff」と言い、大量の粉末の流れで私たちにくしゃみをしました。 そして、それは轟音を立てて起き上がりました。
EMCOPingモニター。 無料の管理アシスタント
インフラストラクチャに最大5つの仮想化ホストがある場合は、無料バージョンを使用できます。
pingモニター:ネットワーク接続状態監視ツール(5つのホストで無料)
情報:
コマンドを実行することでホストのネットワークへの接続を自動的にチェックする信頼性の高い監視ツール ping.
Wiki:
Pingは、TCP / IPベースのネットワークでの接続をテストするためのユーティリティであり、要求自体の一般名でもあります。
ユーティリティは、ICMPプロトコルの要求(ICMP Echo-Request)を指定されたホストに送信し、着信応答(ICMP Echo-Reply)をキャプチャします。 要求を送信してから応答を受信するまでの時間(RTT、英語のラウンドトリップ時間から)を使用すると、ルートに沿ったラウンドトリップ遅延(RTT)とパケット損失の頻度を決定できます。つまり、データチャネルと中間デバイス。
pingプログラムは、TCP / IPネットワークの主要な診断ツールの1つであり、最新のすべてのネットワークオペレーティングシステムの配信に含まれています。
https://ru.wikipedia.org/wiki/Ping
このプログラムは、定期的なICMP要求を送信することにより、ネットワーク接続を監視し、検出されたチャネルの復元/ドロップについて通知します。 EMCO Ping Monitorは、稼働時間、サービスの中断、pingの失敗などを含む接続統計データを提供します。


この光学系の出現により、森を通り抜けてコレクターに到達することで、インストーラーはテクノロジーに少し従わなかったと結論付けることができます。 写真の台紙は、彼がおそらく船乗り、つまり海の結び目であることも示唆しています。
私はフィジカルネットワークヘルスチームに所属しています。つまり、ルータのライトが適切に点滅するようにするためのテクニカルサポートです。 私たちは、全国にインフラストラクチャを備えたさまざまな大企業を抱えています。 私たちは彼らのビジネスの内部に登ることはありません。私たちの仕事は、ネットワークが物理レベルで機能し、トラフィックが正常に通過することを確認することです。
作業の一般的な意味は、ノードの継続的なポーリング、テレメトリの削除、テストの実行(たとえば、脆弱性を見つけるための設定のチェック)、正常性の確保、アプリケーションの監視、トラフィックです。 時々在庫と他の倒錯。
それがどのように構成されているか、そして旅行からのいくつかの話についてお話します。
通常の場合のように
私たちのチームはモスクワのオフィスに座って、ネットワークテレメトリを利用しています。 実際には、これらはノードの一定のpingであり、ハードウェアがスマートである場合は監視データを取得します。 最も一般的な状況は、pingが連続して数回通過しないことです。 たとえば、小売チェーンの場合の80%で、これは停電であることが判明したため、この図を見て、次のことを行います。- まず、事故についてプロバイダーに電話します
- それから-シャットダウンについて発電所に
- 次に、施設の誰かとの接続を確立しようとします(これは、たとえば午前2時に常に可能であるとは限りません)
- そして最後に、上記が5〜10分で役に立たなかった場合、問題があれば、私たちは自分自身を離れるか、「アバター」を送ります。イジェフスクまたはウラジオストクのどこかに座っている契約エンジニアです。
- 私たちは常に「アバター」と連絡を取り、インフラストラクチャを通じて「アバター」を「リード」します。センサーとサービスマニュアルがあり、ペンチがあります。
- 次に、エンジニアはそれが何であったかについての写真付きのレポートを私たちに送信します。
対話は時々次のようになります:
-そのため、建物番号4と5の間の接続が失われます。5番目のルーターを確認してください。
-注文、含まれています。 接続はありません。
-わかりました。ケーブルに沿って4番目の建物に行きます。別のノードがあります。
-…おっパ!
- どうしたの?
-ここで4番目の家が取り壊されました。
- 何??
-レポートに写真を添付しています。 SLAで家を復元することはできません。
しかし、多くの場合、それでも休憩を見つけてチャネルを復元することが判明します。
旅行の約60%は「牛乳の中」です。これは、電源が(シャベル、職長、侵入者によって)中断されているか、プロバイダーがその障害について知らないか、設置者の前に短期間の問題が解消されているためです。到着。 ただし、ユーザーの前やお客様のITサービスの前に問題を発見し、何かが起こったことに気付く前に解決策を伝える場合があります。 ほとんどの場合、このような状況は、顧客企業の活動が少ない夜間に発生します。
誰がそれを必要とし、なぜ
原則として、大企業には独自のIT部門があり、詳細とタスクを明確に理解しています。 中規模および大規模のビジネスでは、「enikeevs」およびネットワークエンジニアの作業は外部委託されることがよくあります。 それはただ有益で便利です。 たとえば、ある小売業者には非常に優秀なIT担当者がいますが、ルーターを交換したりケーブルを追跡したりすることにはほど遠いです。私たちは何をしていますか
- チケットやパニックコールなどのリクエストに対応しています。
- 予防を行います。
- メンテナンスの条件など、ハードウェアベンダーの推奨事項に従います。
- 私たちは顧客の監視に接続し、事件が発生した場合に旅行するために顧客からデータを削除します。
最初の方法(単純なチェック)は、ネットワーク上のすべてのノードにpingを実行し、それらが正しく応答することを確認するマシンです。 このような実装では、顧客のネットワークにまったく変更を加える必要がないか、最小限の変更を加える必要があります。 原則として、非常に単純なケースでは、Zabbixをデータセンターの1つに直接インストールします(幸い、VolochaevskayaのCROCオフィスに2つあります)。 より複雑なものでは、たとえば、独自の安全なネットワークを使用している場合、顧客のデータセンター内のマシンの1つに次のようになります。
Zabbixはより複雑に使用できます。たとえば、エージェントが* nixノードとwinノードにインストールされ、システムモニタリングと、外部チェックモード(SNMPプロトコルのサポート付き)を表示します。 それでも、ビジネスに同様の何かが必要な場合は、すでに独自の監視機能を備えているか、より機能的に豊富なソリューションが選択されます。 もちろん、これはもはやオープンソースではなく、コストもかかりますが、平凡な正確な在庫でさえ、すでにコストを約3分の1上回っています。
私たちもこれを行いますが、これは同僚の話です。 ここで、Infosimのスクリーンショットをいくつか送信しました。
私はアバターオペレーターなので、私の仕事について詳しく説明します。
典型的な事件はどのように見えますか?
私たちの前には、次の一般的なステータスの画面があります。
このオブジェクトに関して、Zabbixは、バッチ番号、シリアル番号、CPU使用率、デバイスの説明、インターフェースの可用性など、非常に多くの情報を収集します。 必要なすべての情報は、このインターフェースから入手できます。
通常のインシデントは、通常、たとえば、顧客の店舗(全国に200〜300個ある店舗)につながるチャネルの1つが脱落するという事実から始まります。 小売業は7年前とは異なり、現在十分に発達しているため、興行収入は引き続き機能します。2つのチャネルがあります。
私たちは電話を取り、少なくとも3つの電話をかけます。プロバイダー、発電所、その場の人々に電話をかけます(「はい、ここにフィッティングをロードしました。誰かのケーブルに触れました...ああ、あなたの?我々はそれを見つけた")。
原則として、監視しないと、エスカレーションの前に数時間または数日が経過します。同じバックアップチャネルが常にチェックされるとは限りません。 私たちはすぐに知って、すぐに去ります。 ping以外の追加情報(たとえば、バグのある鉄片のモデル)がある場合は、必要な部品をフィールドエンジニアにすぐに完成させます。 さらにすでに実施されています。
2番目に頻繁な通常の通話は、ユーザーの端末の1つ、たとえば、ネットワークをオフィスに分散したDECT電話またはWi-Fiルーターの障害です。 ここでは、監視から問題について学び、ほとんどすぐに詳細を記載した電話を受けます。 呼び出しによって新しいものが追加されない場合(「電話を取りましたが、何かが鳴りません」)、非常に便利な場合があります(「テーブルからドロップしました」)。 2番目のケースでは、これは明らかに改行ではないことは明らかです。
モスクワの設備は私たちのホットリザーブ倉庫から取られています、私たちはそれらのいくつかのタイプを持っています:
顧客は通常、頻繁に故障するコンポーネント(オフィスの受話器、電源装置、ファンなど)を自社で在庫しています。 モスクワではなく、所定の場所にないものを配達する必要がある場合、私たちは通常、自分たちで行きます(設置のため)。 たとえば、私はニジニタギルへの夜の旅行をしました。
お客様が独自の監視を行っている場合は、データをアップロードできます。 透明性とSLA制御を確保するために、Zabbixをポーリングモードでデプロイする場合があります(これはお客様にとっても無料です)。 追加のセンサーはインストールしませんが(これは、生産プロセスの継続性を保証する同僚によって行われます)、プロトコルがエキゾチックでない場合はセンサーに接続できます。
通常、お客様のインフラストラクチャには触れず、そのままサポートします。
経験から、コストの面で非常に予測可能であるという事実のために、最後の10人の顧客が外部サポートに切り替えたと言えます。 明確な予算編成、適切なケース管理、各要求に関するレポート、SLA、機器レポート、予防保守。 もちろん、理想的には、私たちはクリーナーなどの顧客のCIOのためです。私たちはやって来て、すべてがきれいで、気を散らさないようにします。
注目に値するもう一つのことは、いくつかの大企業では、在庫が実際の問題になり、時にはそれを実行するためだけに私たちが惹かれることです。 さらに、構成の保存とその管理を行います。これは、さまざまな再配置や再接続に便利です。 しかし、繰り返しになりますが、困難なケースでは、これも私ではありません。データセンターを転送する特別なチームがあります。
そしてもう1つの重要なポイントは、私たちの部門は重要なインフラストラクチャを扱っていないということです。 データセンター内のすべてと銀行保険事業者のすべてに加えて、小売コアシステム-これはXチームです。 これがみんなです。
もっと練習
最近の多くのデバイスは、多くのサービス情報を提供できます。 たとえば、ネットワークプリンタは、カートリッジ内のトナーのレベルを非常に簡単に監視できます。 事前に交換期間を頼りにすることができ、さらに5〜10%の通知を受け取ることができます(オフィスが標準のスケジュールではなく突然激しく入力し始めた場合)-そして経理部門がパニックに陥る前にすぐにenikeyを送信します。非常に多くの場合、年次統計は私たちから奪われます。これは、同じ監視システムと私たちによって行われます。 Zabbixの場合、これは単純なコスト計画と何がどこに行ったかを理解することであり、Infosimの場合は、1年間のスケーリングを計算したり、管理者をロードしたりするための資料でもあります。 統計にはエネルギー消費があります。昨年、ほとんどの人が彼に尋ね始めました。これは明らかに、部門間で内部コストを分散させるためです。
時には本当の英雄的な救助が得られます。 このような状況は非常にまれですが、今年のことを思い出すと、午前3時頃にCiscoスイッチで気温が55度に上昇しました。 遠くのサーバールームには、監視のない「ばかげた」エアコンがあり、故障しました。 私たちはすぐに(私たちではなく)冷却エンジニアに電話し、当直の顧客の管理者に電話しました。 彼はいくつかの重要ではないサービスを出し、男がモバイルエアコンを持って到着するまでサーバールームをサーマルショットダウンから守り、その後通常のエアコンを修理しました。
ポリコムやその他の高価なビデオ会議機器は、会議の前にバッテリーの充電レベルを非常によく監視します。これも重要です。
誰もが監視と診断を必要としています。 原則として、経験なしに実装することは長く困難です。システムは非常に単純で事前構成されているか、空母のサイズであり、多数の標準レポートがあります。 会社のファイルを研ぎ澄まし、社内IT部門のタスクの実装を考案し、最も必要な情報を表示し、さらに、実装の経験がない場合は、履歴全体を最新の状態に保つことは簡単です。 監視システムを使用する場合、無料ソリューションとトップソリューションの間の中庸を選択します。原則として、最も人気のある「厚い」ベンダーではありませんが、問題を明確に解決します。
かつてはかなり非定型の治療がありました。 顧客は、在庫に応じて、ルーターをいくつかの別々の部門に渡す必要がありました。 ルータには、指定されたシリアル番号のモジュールがありました。 ルーターが道路の準備を始めたとき、このモジュールが欠落していることが判明しました。 そして、誰もそれを見つけることができません。 昨年この支店で働いていたエンジニアがすでに引退しており、孫と別の都市に住んでいるという事実によって、問題は少し悪化しています。 彼らは私たちに連絡して、見るように頼みました。 幸い、ハードウェアがシリアル番号に関するレポートを提供し、Infosimがインベントリを作成したため、インフラストラクチャでこのモジュールを数分で見つけて、トポロジについて説明しました。 逃亡者はケーブルで追跡されました-彼はクローゼットの別のサーバールームにいました。 運動の歴史は、彼が同様のモジュールの失敗の後にそこに着いたことを示しました。
Hottabychに関する長編映画のフレームで、カメラに対する住民の態度を正確に説明しています
たくさんのカメラ事件。一度に3台のカメラが故障しました。 セクションの1つでケーブルが断線しました。 インストーラーは新しいものを波形に吹き込みました。3つの部屋のうちの2つは、一連のシャーマニズムの後に上昇しました。 そして3番目はそうではありません。 さらに、彼女がどこにいるのかはまったくはっきりしていません。 私はビデオストリームを上げます-秋の直前の最後のフレーム-4朝、顔にスカーフを着た3人の男性が現れ、下に何か明るいものがあり、カメラが大きく揺れ、落下します。
カメラをセットアップしたら、フェンスを越えて登る「うさぎ」に焦点を合わせる必要があります。 運転中、侵入者が現れる場所をどのように指定するかを考えました。 便利ではありませんでした。私たちがそこにいた15分間で、30人が必要な場所にのみオブジェクトを入力しました。 まっすぐなテーブル。
すでに上記の例を挙げたように、取り壊された建物についての話は冗談ではありません。 機器へのリンクが消えたら。 所定の場所-銅が通過したパビリオンはありません。 パビリオンは取り壊され、ケーブルはなくなりました。 ルーターが停止していることがわかりました。 インストーラーが到着し、探し始めました-ノード間の距離は数キロです。 彼のセットにはVipnetテスターがあり、標準(1つのコネクタから鳴り、別のコネクタから鳴りました)を探しに行きました。 通常、問題はすぐにわかります。
ケーブルの追跡:これは波形の光学部品であり、結び目についての投稿の最上部からの話の続きです。 ここで、結局のところ、絶対に驚くべきインストールに加えて、問題はケーブルがマウントから離れて移動したことでした。 ここですべてを登り、雑多になり、金属構造を緩めます。 プロレタリアートの約5000人目の代表者が光学系を壊しました。
ある施設では、すべてのノードが週に1回程度オフにされていました。そして同時に。 私たちはかなり前からパターンを探していました。 インストーラーは次を検出しました。
- 問題は常に同じ人のシフトで発生します。
- 彼は非常に重いコートを着ているという点で他の人とは異なります。
- ハンガーの後ろに自動機が取り付けられています。
- 先史時代に、誰かがずっと前に機械のカバーを取りました。
- この同志が施設に来ると、彼は服を脱ぎ、彼女は機械の電源を切ります。
- 彼はすぐにそれらをオンに戻します。
夜間に同時に機器の電源を切りました。地元の職人が私たちの電源に接続し、延長コードを取り出して、そこにやかんと電気ストーブを突き刺したことがわかりました。 これらのデバイスが同時に動作すると、パビリオン全体がノックアウトされます。
私たちの広大な国の店舗の1つでは、シフトの終了に伴い、ネットワーク全体が絶えず低下していました。設置者は、すべての電力が照明ラインに供給されていることを確認しました。 店舗内で(エネルギーを大量に消費する)ホールの天井照明がオフになるとすぐに、すべてのネットワーク機器がオフになります。
管理人がシャベルでケーブルを遮った場合がありました。
多くの場合、銅が引き裂かれた波形で横たわっているのを目にします。 かつて、2つのワークショップの間に、地元の職人が保護なしでツイストペアケーブルを転送しただけでした。
文明から離れて、従業員はしばしば彼らが「私たちの」機器にさらされていると不平を言います。一部の遠隔地の配電盤は、当直者と同じ部屋にある場合があります。 したがって、私たちは数回、シフトの開始時にフックまたは詐欺師によって彼らをオフにした有害な祖母に出くわしました。
別の遠い都市 光学系にモップをかけた。 彼らは壁から波形を壊し、それを機器の留め具として使い始めました。
この場合、明らかに栄養に問題があります。
「大きな」監視でできること
Infosimのインストール例を使用して、より深刻なシステムの機能について簡単に説明します。1つのプラットフォームに統合された4つのソリューションがあります。- 障害管理-障害制御とイベント相関。
- パフォーマンス管理。
- インベントリと自動トポロジ検出。
- 構成管理。
別途、在庫について。 モジュールはリストを表示するだけでなく、トポロジ自体も構築します(少なくとも、95%の場合、モジュールはそれを正しく実行しようとします)。 また、使用済みおよびアイドル状態のIT機器(ネットワーク、サーバー機器など)の最新のデータベースを手元に用意して、古い機器(EOS / EOL)を時間どおりに交換することもできます。 一般的に、大企業にとっては便利ですが、中小企業では、これの多くは手作業で行われます。
レポートの例:
- OSの種類、ファームウェア、モデル、機器メーカー別のレポート。
- ネットワーク内の各スイッチの空きポートの数/選択したメーカー別/モデル別/サブネット別などを報告します。
- 指定された期間に新しく追加されたデバイスについてレポートします。
- プリンタのトナー残量低下の警告。
- 遅延と損失に敏感なトラフィック、アクティブおよびパッシブ方式に対する通信チャネルの適合性の評価。
- 通信チャネル(SLA)の品質と可用性の追跡-通信事業者ごとに分類された、通信チャネルの品質に関するレポートの生成。
- 障害制御およびイベント相関機能は、根本原因分析メカニズム(管理者がルールを作成する必要なし)およびAlarmStatesMachineメカニズムを介して実装されます。 根本原因分析は、次の手順に基づいた事故の根本原因の分析です。1.障害サイトの自動検出と特定。 2.緊急事態の数を1つのキーに減らします。 3.障害の結果を特定する-障害によって誰が、何が影響を受けたか。
Stablenet-Embedded Agent(SNEA)-タバコのパックより少し大きいコンピューター。
インストールは、ATM、またはアクセシビリティテストが必要な専用ネットワークセグメントで実行されます。 彼らの助けを借りて、負荷テストが実行されます。
クラウドモニタリング
もう1つのインストールモデルは、クラウドでのSaaSです。 1人のグローバル顧客(ヨーロッパからシベリアへの流通地域を持つ継続的な生産サイクルを持つ会社)のために作られました。完成品の工場や倉庫など、数十の施設。 彼らのチャネルが落ち、彼らのサポートが外国のオフィスから実行された場合、出荷の遅延が始まり、波に沿って、さらなる損失につながりました。 すべての作業はリクエストに応じて行われ、インシデントの調査に多くの時間が費やされました。
私たちは彼らのために特別に監視を設定し、ルーティングとハードウェアの詳細に応じて多くのサイトで監視を終了しました。 これはすべてCROCクラウドで行われました。 彼らはプロジェクトを非常に迅速に完了し、実施しました。
結果は次のとおりです。
- ネットワークインフラストラクチャの管理が部分的に移行されたため、少なくとも50%を最適化することができました。 機器へのアクセス不能、チャネル負荷、製造元が推奨するパラメータを超える:これらはすべて5〜10分以内に修正され、1時間以内に診断および排除されます。
- クラウドからサービスを受けると、お客様はネットワーク監視システムを導入するための資本コストを、いつでも免除できるサービスのサブスクリプション料金の運用コストに振り替えます。
クラウドの利点は、私たちの決定において、いわば彼らのネットワークの上に立って、より客観的に起こるすべてを見ることができるということです。 そのとき、ネットワーク内にいると、障害ノードまでしか画像が表示されず、その背後で何が起こっているのかがわかりません。
最後の写真のカップル
これは「朝のパズル」です。
そして、これは私たちが見つけた宝物です:
これは胸にあったものです:
そして最後に、おかしな外出について。 私はかつて小売施設に行きました。
そこでは次のことが起こりました。最初に、それは屋根から仮天井に滴り始めました。その後、仮天井に湖が形成され、タイルの1つが浸食されて押しつぶされました。 その結果、これらすべてが電気技師に噴出しました。 何が起こったのか正確にはわかりませんが、隣の部屋のどこかで短絡が発生し、火災が発生しました。 最初に、粉末消火器が機能し、次に消防士が到着し、すべてを泡で満たしました。 分解のために彼らの後に到着しました。 私はtsiska2960がこのすべての直後にそれを手に入れたと言わなければなりません-私は設定を拾い上げて、修理のためにデバイスを送ることができました。
もう一度、粉末システムのトリガー中に、1つの缶のTsiskovsky3745がほぼ完全に粉末で満たされました。 すべてのインターフェイスがいっぱいでした-2x48ポート。 それはその場で含まれなければなりませんでした。 私たちは最後のケースを思い出し、構成を「ホット」に削除して、それを振り払い、可能な限りクリーンアップすることにしました。 私たちはそれをオンにしました-最初にデバイスは「pff」と言い、大量の粉末の流れで私たちにくしゃみをしました。 そして、それは轟音を立てて起き上がりました。
エコーリクエスト
エコー要求(ping)は、特定のホストがIPネットワーク上で到達可能かどうかを確認するために使用される診断ツールです。 エコー要求は、ICMP(インターネット制御メッセージプロトコル)プロトコルを使用して行われます。 このプロトコルは、チェック対象のホストにエコー要求を送信するために使用されます。 ホストは、ICMPパケットを受け入れるように構成する必要があります。
審査
エコーリクエストによる
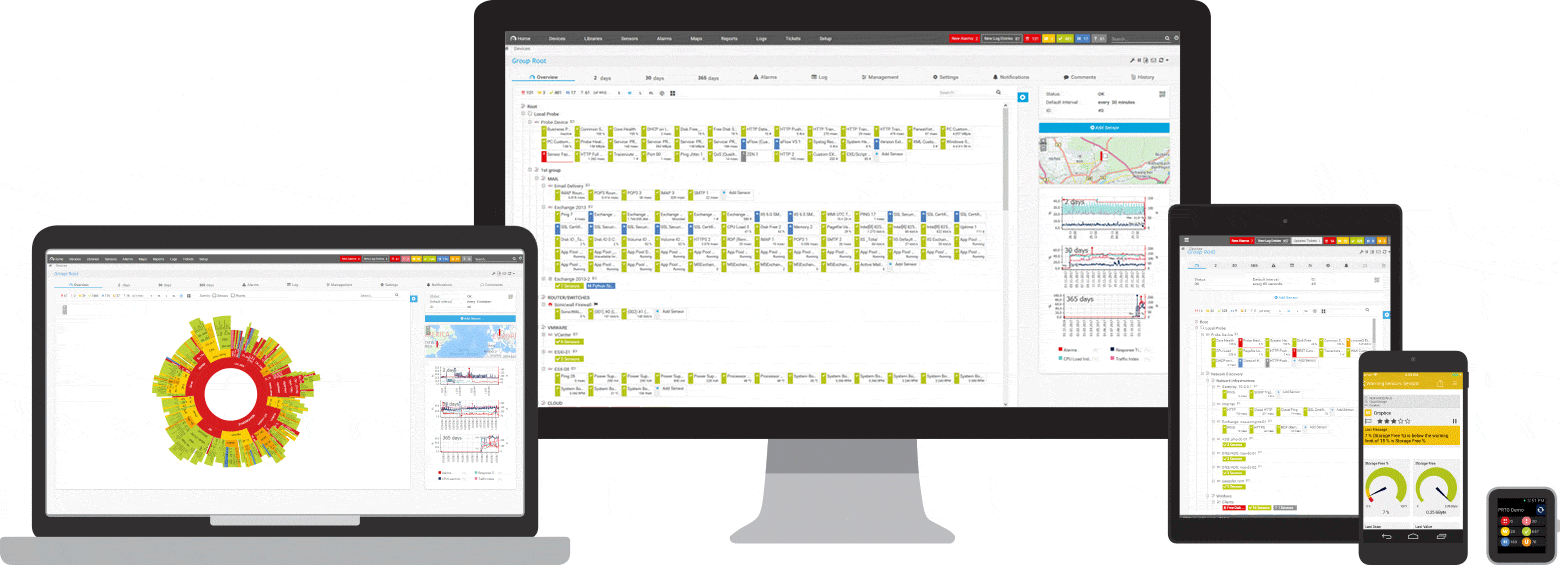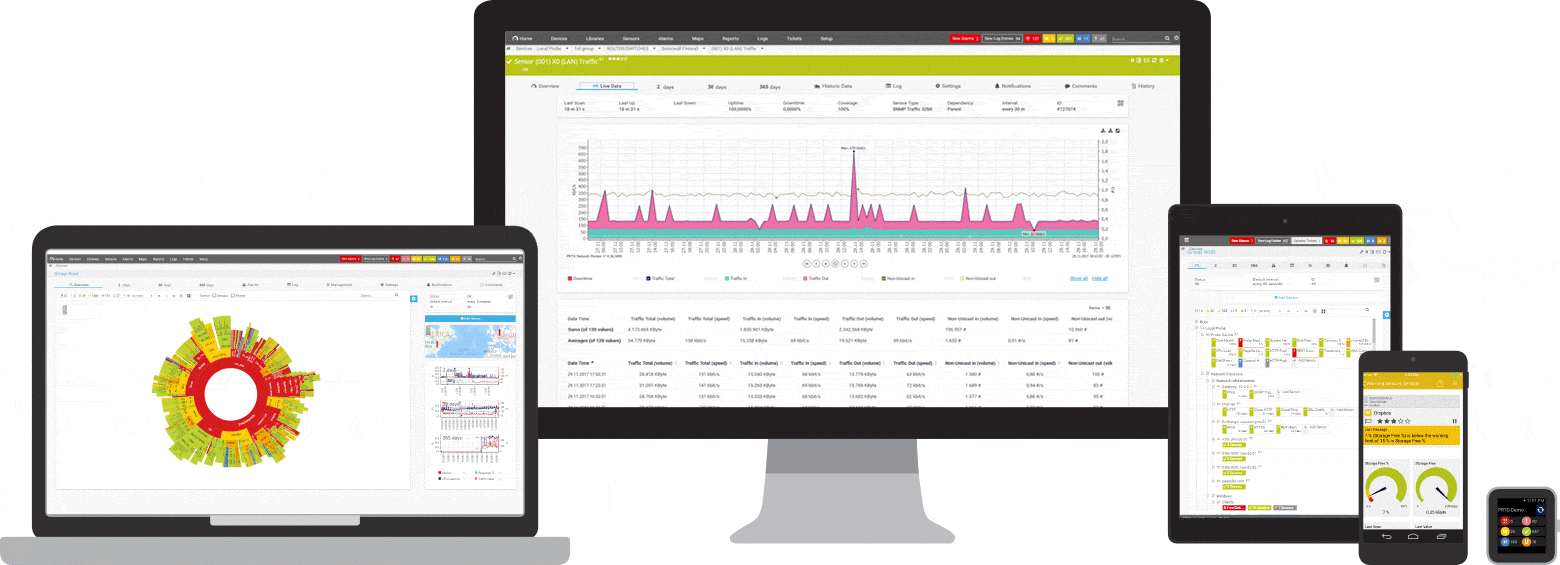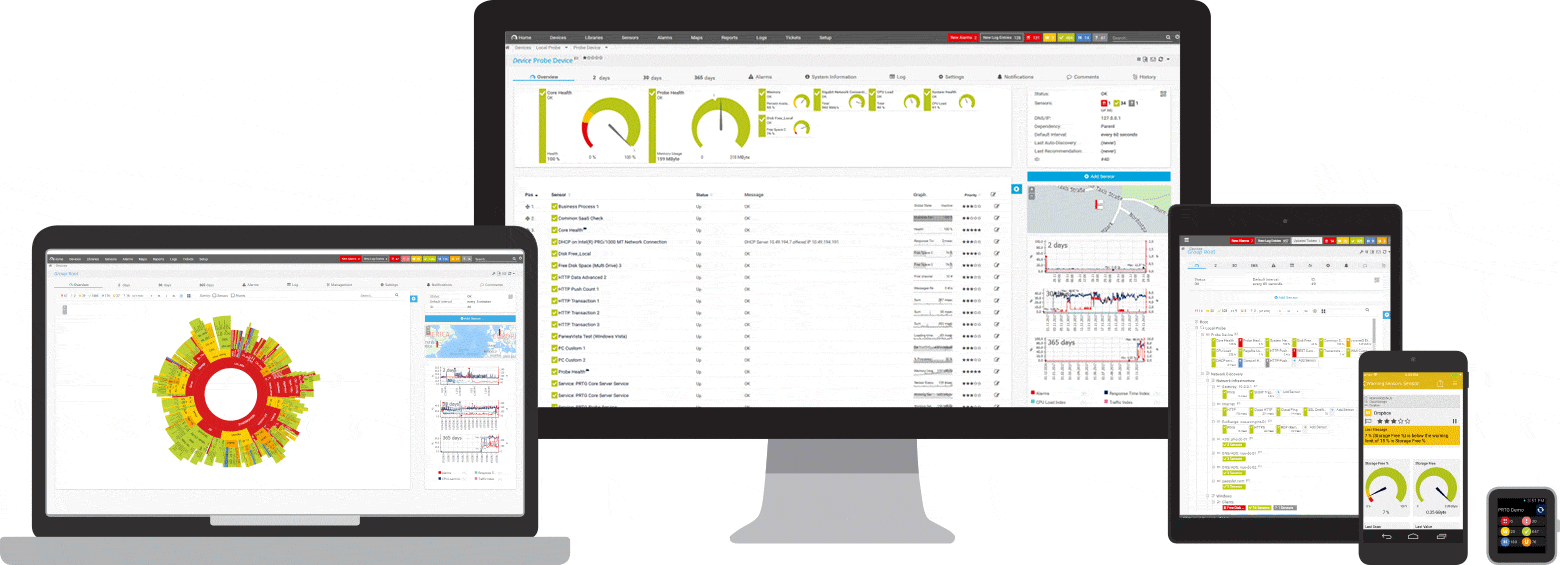
PRTGは、Windows用のpingおよびネットワーク監視ツールです。 これは、Windows Server2012R2およびWindows10を含むすべての主要なWindowsシステムと互換性があります。
PRTGは、ネットワーク全体にとって強力なツールです。 サーバー、ルーター、スイッチ、稼働時間、クラウド接続の場合、PRTGはすべてを追跡するため、管理の手間を省くことができます。 pingセンサー、SNMP、NetFlow、およびパケットスニッフィングセンサーは、ネットワークの可用性とワークロードに関する詳細情報を収集するために使用されます。
PRTGには、問題をすばやく通知するカスタマイズ可能な組み込みのアラームシステムがあります。 pingセンサーは、ネットワークデバイスのプライマリセンサーとして構成されます。 このセンサーに障害が発生すると、デバイス上の他のすべてのセンサーがスリープモードになります。 これは、アラートメッセージのストリームの代わりに、1つの通知のみを受信することを意味します。
いつでも、PRTGダッシュボードに簡単な概要を表示できます。 すべてが正常であるかどうかがすぐにわかります。 ダッシュボードは、特定のニーズに合わせてカスタマイズできます。 サーバールームでの作業など、職場から離れた場所では、スマートフォンアプリケーションを介してPRTGにアクセスでき、1つのイベントを見逃すことはありません。
初期監視は、インストール中にすぐに構成されます。 これは、自動検出機能のおかげで可能になります。PRTGはプライベートIPアドレスにpingを送信し、使用可能なデバイスのセンサーを自動的に作成します。 初めてPRTGを開くと、ネットワークの可用性をすぐに確認できます。
PRTGプログラムには透過的なライセンスモデルがあります。 PRTGは無料でテストできます。 pingセンサーとアラーム機能も無料版に含まれており、無制限の使用期間があります。 会社またはネットワークにさらに多くの機能が必要な場合は、ライセンスを簡単にアップグレードできます。
スクリーンショット
PRTGの簡単な紹介:pingモニタリング



pingセンサーが完全に表示されます
-外出先でも
PRTGは数分でインストールされ、ほとんどのモバイルデバイスと互換性があります。
PRTGは、これらおよび他の多くのメーカーとアプリケーションを管理します
ping監視用の3つのPRTGセンサー
センサー
エコーリクエスト
クラウドから
Cloud Ping Sensorは、PRTG Cloudを使用して、世界中のさまざまな場所からネットワークにpingを実行するのにかかる時間を測定します。 このセンサーを使用すると、アジア、ヨーロッパ、およびアメリカでのネットワークの可用性を確認できます。 特に、この指標は国際企業にとって非常に重要です。 。
PRTGソフトウェアを購入すると、包括的な無料サポートを受けることができます。 私たちの仕事はあなたの問題をできるだけ早く解決することです! 特にこのために、他の資料とともに、トレーニングビデオと包括的なガイドを用意しました。 すべてのサポートチケットに24時間(平日)以内に対応することを目指しています。 ナレッジベースには、多くの質問に対する回答があります。 たとえば、検索クエリ「pingmonitoring」は700件の結果を返します。 いくつかの例:
「デバイスのステータスを変更せずに、デバイスの可用性に関する情報のみを収集するpingセンサーが必要です。 出来ますか?"
「逆エコー要求センサーを構築できますか?」

「PRTGを使用すると、システムが継続的に監視されていることをより快適に知ることができます。」
Markus Puke、ネットワーク管理者、Schüchtermannクリニック(ドイツ)
- 30日間のPRTGのフルバージョン
- 30日後-無料版
- 拡張バージョンの場合-商用ライセンス

| ネットワーク監視ソフトウェア-バージョン19.2.50.2842(2019年5月15日) | |
|
ホスティング |
クラウドバージョンも利用可能(クラウド内のPRTG) |
言語 |
英語、ドイツ語、ロシア語、スペイン語、フランス語、ポルトガル語、オランダ語、日本語、簡体字中国語 |
価格 |
最大100個のセンサーを無料(価格) |
包括的な監視 |
ネットワークデバイス、帯域幅、サーバー、アプリケーション、仮想環境、リモートシステム、IoTなど。 |
サポートされているプロバイダーとアプリケーション |
PRTGによるネットワークとpingの監視:3つの実用的なケーススタディ
世界中の20万人の管理者がPRTGプログラムに依存しています。 これらの管理者はさまざまな業界の出身である可能性がありますが、すべてに共通することが1つあります。それは、ネットワークの可用性とパフォーマンスを確保および改善したいという願望です。 3つのユースケース:

チューリッヒ空港
チューリッヒ空港はスイス最大の空港であるため、すべての電子システムがスムーズに機能することが特に重要です。 これを可能にするために、IT部門はPaesslerAGのPRTGネットワークモニターソフトウェアを実装しました。 4,500を超えるセンサーを備えたこのツールは、ITチームが問題を即座に検出し、解決することを保証します。 これまで、IT部門はさまざまな監視プログラムを使用していました。 しかし、最終的に経営陣は、このソフトウェアは運用および保守担当者による専門的な監視には不適切であると結論付けました。 使用例。

バウハウス大学、ワイマール
ワイマールのバウハウス大学のITシステムは、5,000人の学生と400人の従業員によって使用されています。 以前は、Nagiosに基づく分離ソリューションを使用して大学ネットワークを監視していました。 このシステムは技術的に時代遅れであり、教育機関のITインフラストラクチャのニーズを満たすことができませんでした。 インフラストラクチャのアップグレードには非常に費用がかかります。 代わりに、大学は新しいネットワーク監視ソリューションに目を向けました。 ITエグゼクティブは、ユーザーフレンドリーで、インストールが簡単で、費用対効果の高い包括的なソフトウェア製品を求めていました。 それが彼らがPRTGを選んだ理由です。 使用例。

フランケンタール市の公益事業
フランケンタール市の公益事業の200人をわずかに超える従業員が、個人の消費者や組織への電気、ガス、水の供給に責任を負っています。 組織は、すべての建物とともに、約80台のサーバーと200台の接続されたデバイスで構成されるローカルに分散されたインフラストラクチャにも依存しています。 フランケンタールのITエグゼクティブは、特定のニーズを満たす手頃なソフトウェアを探していました。 まず、ITはPRTGの無料トライアルを設定しました。 フランケンタールの公益事業は現在、約1,500のセンサーを使用して、とりわけ公共のプールを監視しています。 使用例。

実用的なアドバイス。 教えてください、グレッグ、pingを監視するための推奨事項はありますか?
「ピンバックセンサーは、おそらくネットワーク監視の最も重要な要素です。 特に接続を考慮して、適切に構成する必要があります。 たとえば、仮想マシンを監視している場合は、そのホストへの接続にpingセンサーを配置すると便利です。 ノードに障害が発生した場合、ノードに接続されているすべての仮想マシンの通知を受け取ることはありません。 さらに、pingセンサーは、特に高可用性またはフェイルオーバーのシナリオで、ホストまたはインターネットへのネットワークパスが適切に機能していることを示す優れた指標になります。」
PAESSLER AG、システム管理者、Greg Campion