Software de monitorizare Ping. Monitorizarea rețelei: cum ne asigurăm că toate nodurile funcționează pentru companiile mari
Un instrument robust de monitorizare ping pentru verificarea automată a conexiunii la gazdele de rețea. Efectuând ping-uri regulate, monitorizează conexiunile la rețea și vă anunță despre creșterile/coborâșurile detectate. EMCO Ping Monitor oferă, de asemenea, informații despre statistici de conexiune, inclusiv timp de funcționare, întreruperi, ping-uri eșuate etc. Puteți extinde cu ușurință funcționalitatea și configura EMCO Ping Monitor pentru a executa comenzi personalizate sau a lansa aplicații atunci când conexiunile sunt pierdute sau restaurate.
Ce este EMCO Ping Monitor?
EMCO Ping Monitor poate funcționa în modul 24/7 pentru a urmări stările conexiunii uneia sau mai multor gazde. Aplicația analizează răspunsurile ping pentru a detecta întreruperile conexiunii și pentru a raporta statisticile conexiunii. Poate detecta automat întreruperile conexiunii și poate afișa baloane în tava Windows, poate reda sunete și poate trimite notificări prin e-mail. De asemenea, poate genera rapoarte și le poate trimite prin e-mail sau salva ca fișiere PDF sau HTML.
Programul vă permite să obțineți informații despre starea tuturor gazdelor, să verificați statisticile detaliate ale unei gazde selectate și să comparați performanța diferitelor gazde. Programul stochează datele ping colectate în baza de date, astfel încât să puteți verifica statisticile pentru o perioadă de timp selectată. Informațiile disponibile includ timpul de ping min/max/mediu, deviația ping, lista întreruperilor conexiunii etc. Aceste informații pot fi reprezentate ca date de grilă și diagrame.
EMCO Ping Monitor: Cum funcționează?
EMCO Ping Monitor poate fi folosit pentru a efectua monitorizarea ping a doar câteva gazde sau mii de gazde. Toate gazdele sunt monitorizate în timp real prin fire de lucru dedicate, astfel încât să puteți obține statistici în timp real și notificări privind modificările stării conexiunii pentru fiecare gazdă. Programul nu are cerințe speciale pentru hardware - puteți monitoriza câteva mii de gazde pe un computer modern tipic.
Programul folosește ping-uri pentru a detecta întreruperile conexiunii. Dacă câteva ping-uri au eșuat într-un raw - acesta raportează o întrerupere și vă anunță despre problemă. Când conexiunea este stabilită și ping-urile încep să treacă - programul detectează sfârșitul întreruperii și vă anunță despre asta. Puteți personaliza întrerupere și restabili condițiile de detectare, precum și notificările utilizate de program.
Comparați caracteristicile și selectați ediția
Programul este disponibil în trei ediții cu setul diferit de caracteristici.
Compara ediții
Ediția gratuită permite efectuarea de monitorizare ping a până la 5 gazde. Nu permite nicio configurație specifică pentru gazde. Funcționează ca un program Windows, așa că monitorizarea este oprită dacă închideți interfața de utilizare sau vă deconectați de la Windows.
Gratuit pentru uz personal și comercial
Ediție profesională
Ediția Professional permite monitorizarea a până la 250 de gazde simultan. Fiecare gazdă poate avea o configurație personalizată, cum ar fi, notificarea destinatarilor de e-mail sau acțiuni personalizate care trebuie executate în cazul pierderii conexiunii și evenimentelor de restabilire. Funcționează ca un serviciu Windows, așa că monitorizarea continuă chiar dacă închideți interfața de utilizare sau vă deconectați de la Windows.
Enterprise Edition
Ediția Enterprise nu are limitări privind numărul de gazde monitorizate. Pe un PC modern, este posibil să monitorizați peste 2500 de gazde, în funcție de configurația hardware.
Această ediție include toate caracteristicile disponibile și funcționează ca client/server. Serverul funcționează ca un serviciu Windows pentru a asigura monitorizarea ping-ului în modul 24/7. Clientul este un program Windows care se poate conecta la un server care rulează pe un PC local sau la un server la distanță printr-o rețea LAN sau Internet. Mai mulți clienți se pot conecta la același server și pot lucra concomitent.
Această ediție include și rapoarte web, care permit revizuirea statisticilor de monitorizare a gazdei de la distanță într-un browser web.
Principalele caracteristici ale EMCO Ping Monitor
Monitorizare ping multi-gazdă
Aplicația poate monitoriza mai multe gazde simultan. Ediția gratuită a aplicației permite monitorizarea a până la cinci gazde; ediția Professional nu are nicio limitare pentru numărul de gazde monitorizate.Monitorizarea fiecărei gazde funcționează independent de alte gazde.Puteți monitoriza zeci de mii de gazde de pe un computer modern.
Detectare întreruperi de conexiune
Aplicația trimite solicitări ICMP ping echo și analizează răspunsurile ping echo pentru a monitoriza starea conexiunii în modul 24/7. Dacă numărul prestabilit de ping-uri eșuează la rând, aplicația detectează o întrerupere a conexiunii și vă anunță problema. Aplicația urmărește toate întreruperile, astfel încât să puteți vedea când o gazdă a fost offline.
Analiza calității conexiunii
Când aplicația trimite ping la o gazdă monitorizată, salvează și agregează date despre fiecare ping, astfel încât să puteți obține informații despre timpii de răspuns ping minim, maxim și mediu și abaterea răspunsului ping de la media pentru orice perioadă de raportare. Acest lucru vă permite să estimați calitatea conexiunii la rețea.
Notificări flexibile
Dacă doriți să primiți notificări despre conexiune pierdută, conexiune restaurată și alte evenimente detectate de aplicație, puteți configura aplicația să trimită notificări prin e-mail, să redă sunete și să arate baloane din tava Windows. Aplicația poate trimite o singură notificare de orice tip sau poate repeta notificări de mai multe ori.
Diagrame și rapoarte
Toate informațiile statistice colectate de aplicație pot fi reprezentate vizual prin diagrame. Puteți vedea statisticile privind ping-ul și timpul de funcționare pentru o singură gazdă și puteți compara performanța mai multor gazde pe diagrame. Aplicația poate genera automat rapoarte în diferite formate în mod regulat pentru a reprezenta statisticile gazdei.
Acțiuni personalizate
Puteți integra aplicația cu software extern executând scripturi externe sau fișiere executabile atunci când conexiunile sunt pierdute sau restaurate sau în cazul altor evenimente. De exemplu, puteți configura aplicația să ruleze un instrument extern de linie de comandă pentru a trimite notificări prin SMS despre orice modificări ale stărilor gazdei.
Prin apariția acestei optici, mergând prin pădure până la colector, putem concluziona că instalatorul nu a respectat puțin tehnologia. Montura din fotografie sugerează, de asemenea, că este probabil un marinar - un nod marin.
Sunt în echipa de sănătate a rețelei fizice, cu alte cuvinte, suport tehnic, care este responsabil pentru a se asigura că luminile de pe routere clipesc așa cum ar trebui. Avem sub aripa noastră diverse mari companii cu infrastructură în toată țara. Nu urcăm în interiorul afacerilor lor, sarcina noastră este să ne asigurăm că rețeaua funcționează la nivel fizic și traficul trece așa cum trebuie.
Sensul general al lucrării este sondarea constantă a nodurilor, eliminarea telemetriei, rulările de testare (de exemplu, verificarea setărilor pentru a găsi vulnerabilități), asigurarea sănătății, monitorizarea aplicațiilor, traficul. Uneori inventare și alte perversiuni.
Vă voi spune despre cum este organizat și câteva povești din excursii.
Așa cum este de obicei cazul
Echipa noastră se află într-un birou din Moscova și preia telemetria rețelei. De fapt, acestea sunt ping-uri constante ale nodurilor, precum și primirea datelor de monitorizare dacă hardware-ul este inteligent. Cea mai frecventă situație este aceea că ping-ul nu trece de mai multe ori la rând. În 80% din cazuri, pentru un lanț de vânzare cu amănuntul, de exemplu, aceasta se dovedește a fi o pană de curent, așa că, văzând această imagine, facem următoarele:- Mai întâi sunăm furnizorul despre accidente
- Apoi - la centrala electrică despre oprire
- Apoi încercăm să stabilim o conexiune cu cineva din unitate (acest lucru nu este întotdeauna posibil, de exemplu, la 2 dimineața)
- Și, în cele din urmă, dacă cele de mai sus nu au ajutat în 5-10 minute, ne părăsim sau trimitem un „avatar” - un inginer contractual care stă undeva în Izhevsk sau Vladivostok, dacă problema este acolo.
- Tinem in permanenta legatura cu “avatarul” si il “conducem” prin infrastructura – avem senzori si manuale de service, el are clesti.
- Apoi inginerul ne trimite un raport cu o fotografie despre ce a fost.
Dialogul sună uneori astfel:
- Deci, conexiunea se pierde între clădirile numărul 4 și 5. Verificați routerul în a cincea.
- Comanda, inclusa. Nu există nicio legătură.
- Ok, mergi de-a lungul cablului până la a patra clădire, există un alt nod.
-... Oppa!
- Ce s-a întâmplat?
- Aici casa a 4-a a fost demolată.
- Ce??
- Atasez o fotografie la raport. Nu pot restaura casa în SLA.

Dar mai des, se dovedește totuși să găsească o pauză și să restabilească canalul.
Aproximativ 60% din călătorii sunt „în lapte”, deoarece fie alimentarea cu energie este întreruptă (de o lopată, maistru, intruși), fie furnizorul nu știe de eșecul acesteia, fie o problemă pe termen scurt este eliminată înainte de instalator ajunge. Cu toate acestea, există momente când aflăm despre problemă înaintea utilizatorilor și înaintea serviciilor IT ale clientului și comunicăm soluția înainte ca aceștia să realizeze că s-a întâmplat ceva. Cel mai adesea, astfel de situații apar noaptea, când activitatea în companiile clienți este scăzută.
Cine are nevoie și de ce
De regulă, orice companie mare are propriul departament IT, care înțelege clar specificul și sarcinile. În întreprinderile medii și mari, munca „enikeev” și a inginerilor de rețea este adesea externalizată. Este doar benefic și convenabil. De exemplu, un comerciant cu amănuntul are propriii săi oameni IT foarte cool, dar sunt departe de a înlocui routerele și de a urmări cablurile.Ce facem
- Lucrăm la solicitări - bilete și apeluri de panică.
- Facem prevenire.
- Urmăm recomandările vânzătorilor de hardware, de exemplu, cu privire la condițiile de întreținere.
- Ne conectăm la monitorizarea clientului și eliminăm date de la acesta pentru a călători în caz de incidente.
Prima modalitate - verificări simple - este doar o mașină care trimite ping la toate nodurile din rețea și se asigură că acestea răspund corect. O astfel de implementare nu necesită deloc modificări sau modificări cosmetice minime în rețeaua clientului. De regulă, într-un caz foarte simplu, instalăm Zabbix direct la noi înșine într-unul dintre centrele de date (din fericire, avem două dintre ele în biroul CROC de pe Volochaevskaya). Într-una mai complexă, de exemplu, dacă utilizați propria rețea securizată - la una dintre mașinile din centrul de date al clientului:

Zabbix poate fi folosit mai complicat, de exemplu, are agenți care sunt instalați pe nodurile * nix și win și arată monitorizarea sistemului, precum și modul de verificare extern (cu suport pentru protocolul SNMP). Cu toate acestea, dacă o afacere are nevoie de ceva similar, atunci fie are deja propria lor monitorizare, fie se alege o soluție mai bogată funcțional. Desigur, acesta nu mai este open source și costă bani, dar chiar și un inventar exact banal bate deja costurile cu aproximativ o treime.
Facem și asta, dar aceasta este povestea colegilor. Aici au trimis câteva capturi de ecran ale Infosim:


Sunt un operator avatar, așa că vă voi spune mai multe despre munca mea.
Cum arată un incident tipic?
În fața noastră sunt ecrane cu următoarea stare generală:
Pe acest site, Zabbix colectează destul de multe informații pentru noi: număr de piesă, număr de serie, utilizarea procesorului, descrierea dispozitivului, disponibilitatea interfețelor etc. Toate informațiile necesare sunt disponibile din această interfață.
Un incident obișnuit începe de obicei cu faptul că unul dintre canalele care duc spre, de exemplu, magazinul clientului (din care are 200-300 de bucăți în toată țara) cade. Retailul este acum bine dezvoltat, nu ca acum șapte ani, așa că box office-ul va continua să funcționeze - există două canale.
Luăm telefoanele și facem cel puțin trei apeluri: către furnizor, centrală și oamenii de la fața locului („Da, am încărcat fitinguri aici, s-a atins cablul cuiva... A, al tău? Ei bine, e bine că am găsit-o").
De regulă, fără monitorizare, înainte de escaladare ar trece ore sau zile - aceleași canale de rezervă nu sunt întotdeauna verificate. Știm imediat și plecăm imediat. Dacă există informații suplimentare, altele decât ping-uri (de exemplu, un model al unei piese de fier buggy), completăm imediat inginerul de teren cu piesele necesare. Mai departe, deja pe loc.
Al doilea cel mai frecvent apel obișnuit este defectarea unuia dintre terminalele pentru utilizatori, de exemplu, un telefon DECT sau un router Wi-Fi care a distribuit rețeaua la birou. Aici aflăm despre problemă din monitorizare și aproape imediat primim un apel cu detalii. Uneori apelul nu adaugă nimic nou („Ridic telefonul, ceva nu sună”), uneori este foarte util („L-am scăpat de la masă”). Este clar că, în al doilea caz, aceasta nu este clar o întrerupere de linie.
Echipamentele din Moscova sunt luate din depozitele noastre de rezervă, avem mai multe tipuri:

Clienții au de obicei propriile stocuri de componente care se defectează frecvent - telefoane de birou, surse de alimentare, ventilatoare și așa mai departe. Dacă trebuie să livrați ceva care nu este la locul lui, nu la Moscova, de obicei mergem singuri (din cauza instalării). De exemplu, am avut o excursie de noapte la Nijni Tagil.
Dacă clientul are propria monitorizare, poate încărca date către noi. Uneori implementăm Zabbix în modul de sondare, doar pentru a asigura transparența și controlul SLA (acest lucru este gratuit și pentru client). Nu instalăm senzori suplimentari (asta se face de către colegi care asigură continuitatea proceselor de producție), dar ne putem conecta la aceștia dacă protocoalele nu sunt exotice.
În general, nu atingem infrastructura clientului, ci doar o susținem așa cum este.
Din experiență pot spune că ultimii zece clienți au trecut la suport extern datorită faptului că suntem foarte previzibili din punct de vedere al costurilor. Bugetare clară, management bun de caz, raport pentru fiecare cerere, SLA, rapoarte de echipamente, întreținere preventivă. În mod ideal, desigur, suntem pentru CIO al unui client precum curățenii – venim și facem asta, totul este curat, nu distragem atenția.
Un alt lucru demn de remarcat este că, în unele companii mari, inventarul devine o problemă reală și, uneori, suntem atrași doar de a le realiza. În plus, facem stocarea configurațiilor și gestionarea acestora, ceea ce este convenabil pentru diferite relocari și reconectări. Dar, din nou, în cazurile dificile, nici acesta nu sunt eu - avem unul special care transportă centre de date.
Și încă un punct important: departamentul nostru nu se ocupă de infrastructura critică. Totul din centrele de date și tot ce este bancar-operator de asigurări, plus sistemele de bază de retail - aceasta este o echipă X. acesti baieti.
Mai practic
Multe dispozitive moderne sunt capabile să ofere o mulțime de informații de service. De exemplu, imprimantele de rețea sunt foarte ușor de monitorizat nivelul de toner din cartuș. Poți conta pe perioada de înlocuire în avans, plus să ai o notificare de 5-10% (dacă biroul începe brusc să scrie cu furie nu în programul standard) - și să trimiți imediat un enikey înainte ca departamentul de contabilitate să intre în panică.De foarte multe ori ni se iau statisticile anuale, ceea ce se face de acelasi sistem de monitorizare plus noi. În cazul Zabbix, aceasta este o simplă planificare a costurilor și înțelegerea a ceea ce a mers prost, iar în cazul Infosim, este, de asemenea, material pentru calcularea scalării pentru un an, încărcarea administratorilor și tot felul de alte lucruri. În statistică este consum de energie - în ultimul an aproape toată lumea a început să-l întrebe, se pare că pentru a împrăștia costurile interne între departamente.
Uneori se obțin adevărate salvări eroice. Asemenea situații sunt foarte rare, dar din câte îmi amintesc anul acesta, am văzut în jurul orei 3 dimineața că temperatura a urcat la 55 de grade la comutatorul Cisco. În camera de server îndepărtată erau aparate de aer condiționat „prostice” fără monitorizare și au eșuat. Am sunat imediat un inginer de răcire (nu al nostru) și am chemat administratorul clientului de serviciu. A pus niște servicii necritice și a păstrat camera serverelor de la doborârea termică până a sosit tipul cu un aparat de aer condiționat mobil, iar apoi au fost reparate cele obișnuite.
Polycoms și alte echipamente scumpe de videoconferință monitorizează foarte bine nivelul de încărcare a bateriei înainte de conferințe, ceea ce este de asemenea important.
Toată lumea are nevoie de monitorizare și diagnosticare. De regulă, este lung și dificil de implementat fără experiență: sistemele sunt fie extrem de simple și preconfigurate, fie de dimensiunea unui portavion și cu o grămadă de rapoarte standard. Ascuțirea cu un fișier pentru companie, inventarea implementării sarcinilor acestora pentru departamentul IT intern și afișarea informațiilor de care au cel mai mult nevoie, plus păstrarea la zi a întregului istoric este o greșeală dacă nu există experiență de implementare. Când lucrăm cu sisteme de monitorizare, alegem mijlocul de aur între soluțiile gratuite și cele de top - de regulă, nu cei mai populari și „groși” furnizori, dar rezolvând clar problema.
Odată a existat un tratament destul de atipic. Clientul a trebuit să dea routerul unora dintre diviziile sale separate și exact conform inventarului. Routerul avea un modul cu numărul de serie specificat. Când routerul a început să se pregătească pentru drum, s-a dovedit că acest modul lipsea. Și nimeni nu o poate găsi. Problema este ușor agravată de faptul că inginerul care a lucrat anul trecut cu această ramură este deja pensionar și a plecat să locuiască cu nepoții săi în alt oraș. Ne-au contactat și ne-au cerut să ne uităm. Din fericire, hardware-ul a dat rapoarte privind numerele de serie, iar Infosim a făcut un inventar, așa că în câteva minute am găsit acest modul în infrastructură și am descris topologia. Fugarul a fost urmărit prin cablu - se afla într-o altă cameră de server într-un dulap. Istoria mișcării a arătat că a ajuns acolo după eșecul unui modul similar.

Un cadru dintr-un lungmetraj despre Hottabych, care descrie cu exactitate atitudinea populației față de camere
O mulțime de incidente cu camera. Odată, 3 camere au eșuat simultan. Rupere cablu într-una din secțiuni. Instalatorul a suflat unul nou în ondulat, două dintre cele trei camere s-au ridicat după o serie de șamanism. Iar al treilea nu este. Mai mult, nu este deloc clar unde se află. Ridic fluxul video - ultimele cadre chiar înainte de toamnă - 4 dimineața, trei bărbați în eșarfe pe față urcă, ceva strălucitor dedesubt, camera tremură mult, cade.
Odată ce am instalat camera, care ar trebui să se concentreze pe „iepurii de câmp” care se cațără peste gard. În timpul conducerii, ne-am gândit cum am desemna punctul în care ar trebui să apară intrusul. Nu a fost de folos - în cele 15 minute în care am fost acolo, 30 de persoane au intrat în obiect doar în punctul de care aveam nevoie. Masă dreaptă.
După cum am dat deja un exemplu mai sus, povestea despre clădirea demolată nu este o glumă. Odată ce legătura către echipament a dispărut. Pe loc - nu există nici un pavilion pe unde a trecut cuprul. Pavilionul a fost demolat, cablul a dispărut. Am văzut că routerul era mort. Instalatorul a sosit, a început să caute - iar distanța dintre noduri este de câțiva kilometri. Are un tester Vipnet în setul său, standardul - a sunat de la un conector, a sunat de la altul - s-a dus să caute. De obicei, problema este imediat vizibilă.

Urmărirea cablului: aceasta este optică ondulată, o continuare a poveștii din partea de sus a postării despre nod. Aici, până la urmă, pe lângă instalarea absolut uimitoare, problema era că cablul se îndepărtase de monturi. Aici urcați pe toți și pe toate și slăbiți structurile metalice. Aproximativ cinci mii de reprezentant al proletariatului a spart optica.
La o unitate, toate nodurile au fost oprite aproximativ o dată pe săptămână.Și în același timp. Căutăm un model de ceva timp. Programul de instalare a găsit următoarele:
- Problema apare întotdeauna în tura aceleiași persoane.
- Se deosebește de ceilalți prin faptul că poartă o haină foarte grea.
- O mașină automată este montată în spatele unui cuier.
- Cineva a luat capacul mașinii cu mult timp în urmă, în timpuri preistorice.
- Când această tovarășă vine la clădire, el își închide hainele, iar ea oprește aparatele.
- Le pornește imediat.
Echipamentul a fost oprit la una și aceeași oră, la aceeași oră, noaptea. S-a dovedit că meșterii locali s-au conectat la sursa noastră de alimentare, au scos un prelungitor și au înfipt acolo un fierbător și o sobă electrică. Când aceste dispozitive funcționează simultan, întregul pavilion este dezactivat.
Într-unul dintre magazinele țării noastre vaste, întreaga rețea se prăbuși constant odată cu închiderea turei. Instalatorul a văzut că toată puterea a fost adusă la linia de iluminat. De îndată ce iluminatul de deasupra holului (care consumă multă energie) este stins în magazin, toate echipamentele de rețea sunt oprite.
A existat un caz în care portarul a întrerupt cablul cu o lopată.
Adesea vedem doar cupru culcat cu o ondulare ruptă. Odată, între două ateliere, meșterii locali au trimis pur și simplu un cablu torsadat fără nicio protecție.
Departe de civilizație, angajații se plâng adesea că sunt expuși echipamentelor „noastre”. Panourile de distribuție din unele locații îndepărtate pot fi în aceeași cameră cu persoana de serviciu. În consecință, de câteva ori am dat peste bunici dăunătoare, care, prin cârlig sau prin escroc, le-au oprit la începutul turei.
Un alt oraș îndepărtat a atârnat un mop pe optică. Au rupt ondularea de pe perete, au început să o folosească ca elemente de fixare pentru echipamente.

În acest caz, există clar probleme cu alimentația.
Ce poate face monitorizarea „mare”.
Voi vorbi pe scurt despre capacitățile sistemelor mai serioase, folosind exemplul instalărilor Infosim. Există 4 soluții combinate într-o singură platformă:- Managementul defecțiunilor - controlul defecțiunilor și corelarea evenimentelor.
- Managementul performantei.
- Inventar și descoperire automată a topologiei.
- Managementul configurației.
Separat, despre inventar. Modulul nu numai că arată lista, dar construiește și topologia în sine (cel puțin în 95% din cazuri încearcă și reușește). De asemenea, vă permite să aveți la îndemână o bază de date actualizată cu echipamente IT uzate și inactive (rețea, echipamente server etc.), pentru a înlocui la timp echipamentele învechite (EOS/EOL). În general, este convenabil pentru întreprinderile mari, dar în întreprinderile mici, o mare parte din acest lucru se face manual.
Exemple de rapoarte:
- Rapoarte pe tip de OS, firmware, modele și producători de echipamente;
- Raportați numărul de porturi libere pe fiecare switch din rețea / după producătorul selectat / după model / după subrețea etc.;
- Raportare asupra dispozitivelor nou adăugate pentru o perioadă specificată;
- Avertisment de toner scăzut al imprimantei;
- Evaluarea caracterului adecvat al canalului de comunicație pentru trafic sensibil la întârzieri și pierderi, metode active și pasive;
- Urmărirea calității și disponibilității canalelor de comunicații (SLA) - generarea de rapoarte privind calitatea canalelor de comunicații, defalcate pe operatori de telecomunicații;
- Funcționalitatea de control al eșecurilor și corelarea evenimentelor este implementată prin mecanismul de analiză a cauzei fundamentale (fără a fi nevoie ca administratorii să scrie reguli) și mecanismul Alarm States Machine. Root-Cause Analysis este o analiză a cauzei fundamentale a unui accident bazată pe următoarele proceduri: 1. detectarea și localizarea automată a locului de defecțiune; 2. reducerea numărului de evenimente de urgență la o singură cheie; 3. identificarea consecințelor unui eșec – cine și ce a fost afectat de eșec.

Stablenet - Agent încorporat (SNEA) - un computer puțin mai mare decât un pachet de țigări.
Instalarea se realizează în ATM-uri sau în segmente de rețea dedicate unde este necesară testarea accesibilității. Cu ajutorul lor, se efectuează testarea încărcării.
Monitorizare cloud
Un alt model de instalare este SaaS în cloud. Realizat pentru un singur client global (o companie cu un ciclu de producție continuu cu o geografie de distribuție din Europa în Siberia).Zeci de facilități, inclusiv fabrici și depozite pentru produse finite. Dacă canalele lor au căzut și sprijinul lor a fost efectuat de la birourile externe, atunci au început întârzierile de expediere, care, de-a lungul valului, au dus la pierderi suplimentare. Toate lucrările au fost făcute la cerere și s-a cheltuit mult timp pentru investigarea incidentului.
Am configurat monitorizarea special pentru ei, apoi am terminat-o pe o serie de site-uri în funcție de specificul rutării și hardware-ului lor. Toate acestea au fost făcute în cloud-ul CROC. Au finalizat și livrat proiectul foarte repede.
Rezultatul este:
- Datorită transferului parțial al managementului infrastructurii de rețea, a fost posibilă optimizarea a cel puțin 50%. Inaccesibilitatea echipamentelor, încărcarea canalului, depășirea parametrilor recomandați de producător: toate acestea sunt reparate în 5-10 minute, diagnosticate și eliminate în decurs de o oră.
- Atunci când primește un serviciu din cloud, clientul transferă costurile de capital ale implementării sistemului său de monitorizare a rețelei în costuri de operare pentru o taxă de abonament pentru serviciul nostru, la care poate fi renunțată în orice moment.
Avantajul cloud-ului este că în decizia noastră stăm, parcă, deasupra rețelei lor și putem privi tot ce se întâmplă mai obiectiv. La acel moment, dacă am fi în interiorul rețelei, am vedea poza doar până la nodul de defecțiune, iar ce se întâmplă în spatele ei, nu am mai ști.
Câteva ultime poze
Acesta este „puzzle-ul de dimineață”:
Și aceasta este comoara pe care am găsit-o:

Iată ce era în piept:

Și în sfârșit, despre cea mai amuzantă ieșire. Am fost odată la o unitate de vânzare cu amănuntul.
Acolo s-au întâmplat următoarele: mai întâi, a început să picure de pe acoperiș pe tavanul fals. Apoi s-a format în tavanul fals un lac, care a erodat și a zdrobit una dintre plăci. Drept urmare, toate acestea au țâșnit la electrician. Apoi nu știu exact ce s-a întâmplat, dar undeva în camera alăturată a fost un scurtcircuit și a început un incendiu. Mai întâi au funcționat stingătoarele cu pulbere, iar apoi au sosit pompierii care au umplut totul cu spumă. Am ajuns dupa ei pentru demontare. Trebuie să spun că 2960 tsiska a avut ideea după toate acestea - am putut să ridic configurația și să trimit dispozitivul pentru reparație.
Încă o dată, în timpul declanșării sistemului de pulbere, Tsiskovsky 3745 într-un borcan a fost aproape complet umplut cu pulbere. Toate interfețele erau pline - 2 x 48 porturi. Trebuia inclus pe loc. Și-au amintit ultimul caz, au decis să încerce să elimine configurațiile „fierbinte”, l-au scuturat, l-au curățat cât au putut de bine. L-am pornit - la început dispozitivul a spus „pff” și ne-a strănutat cu un jet mare de pulbere. Și apoi a bubuit și s-a ridicat.
Monitor Ping EMCO. Asistent de administrare gratuit
Dacă infrastructura dumneavoastră are până la 5 gazde de virtualizare, puteți utiliza versiunea gratuită.
Ping Monitor: Instrument de monitorizare a stării conexiunii la rețea (gratuit pentru 5 gazde)
Info:
Instrument de monitorizare de încredere pentru a verifica automat conexiunea la rețeaua de gazde prin executarea unei comenzi ping.
Wiki:
Ping este un utilitar pentru testarea conexiunilor pe rețelele bazate pe TCP/IP, precum și numele comun pentru cererea în sine.
Utilitarul trimite cereri (ICMP Echo-Request) ale protocolului ICMP către gazda specificată și captează răspunsurile primite (ICMP Echo-Reply). Timpul dintre trimiterea unei cereri și primirea unui răspuns (RTT, din engleza Round Trip Time) vă permite să determinați întârzierile dus-întors (RTT) de-a lungul rutei și frecvența pierderii pachetelor, adică să determinați indirect aglomerația pe canale de date și dispozitive intermediare.
Programul ping este unul dintre principalele instrumente de diagnosticare în rețelele TCP / IP și este inclus în livrarea tuturor sistemelor de operare de rețea moderne.
https://ru.wikipedia.org/wiki/Ping
Programul, prin trimiterea de solicitări ICMP regulate, monitorizează conexiunile la rețea și vă anunță despre restabilirea/scăderea canalelor detectată. EMCO Ping Monitor oferă date statistice de conexiune, inclusiv timp de funcționare, întreruperi ale serviciului, eșecuri de ping etc.


Prin apariția acestei optici, mergând prin pădure până la colector, putem concluziona că instalatorul nu a respectat puțin tehnologia. Montura din fotografie sugerează, de asemenea, că este probabil un marinar - un nod marin.
Sunt în echipa de sănătate a rețelei fizice, cu alte cuvinte, suport tehnic, care este responsabil pentru a se asigura că luminile de pe routere clipesc așa cum ar trebui. Avem sub aripa noastră diverse mari companii cu infrastructură în toată țara. Nu urcăm în interiorul afacerilor lor, sarcina noastră este să ne asigurăm că rețeaua funcționează la nivel fizic și traficul trece așa cum trebuie.
Sensul general al lucrării este sondarea constantă a nodurilor, eliminarea telemetriei, rulările de testare (de exemplu, verificarea setărilor pentru a găsi vulnerabilități), asigurarea sănătății, monitorizarea aplicațiilor, traficul. Uneori inventare și alte perversiuni.
Vă voi spune despre cum este organizat și câteva povești din excursii.
Așa cum este de obicei cazul
Echipa noastră se află într-un birou din Moscova și preia telemetria rețelei. De fapt, acestea sunt ping-uri constante ale nodurilor, precum și primirea datelor de monitorizare dacă hardware-ul este inteligent. Cea mai frecventă situație este aceea că ping-ul nu trece de mai multe ori la rând. În 80% din cazuri, pentru un lanț de vânzare cu amănuntul, de exemplu, aceasta se dovedește a fi o pană de curent, așa că, văzând această imagine, facem următoarele:- Mai întâi sunăm furnizorul despre accidente
- Apoi - la centrala electrică despre oprire
- Apoi încercăm să stabilim o conexiune cu cineva din unitate (acest lucru nu este întotdeauna posibil, de exemplu, la 2 dimineața)
- Și, în cele din urmă, dacă cele de mai sus nu au ajutat în 5-10 minute, ne părăsim sau trimitem un „avatar” - un inginer contractual care stă undeva în Izhevsk sau Vladivostok, dacă problema este acolo.
- Tinem in permanenta legatura cu “avatarul” si il “conducem” prin infrastructura – avem senzori si manuale de service, el are clesti.
- Apoi inginerul ne trimite un raport cu o fotografie despre ce a fost.
Dialogul sună uneori astfel:
- Deci, conexiunea se pierde între clădirile numărul 4 și 5. Verificați routerul în a cincea.
- Comanda, inclusa. Nu există nicio legătură.
- Ok, mergi de-a lungul cablului până la a patra clădire, există un alt nod.
-... Oppa!
- Ce s-a întâmplat?
- Aici casa a 4-a a fost demolată.
- Ce??
- Atasez o fotografie la raport. Nu pot restaura casa în SLA.
Dar mai des, se dovedește totuși să găsească o pauză și să restabilească canalul.
Aproximativ 60% din călătorii sunt „în lapte”, deoarece fie alimentarea cu energie este întreruptă (de o lopată, maistru, intruși), fie furnizorul nu știe de eșecul acesteia, fie o problemă pe termen scurt este eliminată înainte de instalator ajunge. Cu toate acestea, există momente când aflăm despre problemă înaintea utilizatorilor și înaintea serviciilor IT ale clientului și comunicăm soluția înainte ca aceștia să realizeze că s-a întâmplat ceva. Cel mai adesea, astfel de situații apar noaptea, când activitatea în companiile clienți este scăzută.
Cine are nevoie și de ce
De regulă, orice companie mare are propriul departament IT, care înțelege clar specificul și sarcinile. În întreprinderile medii și mari, munca „enikeev” și a inginerilor de rețea este adesea externalizată. Este doar benefic și convenabil. De exemplu, un comerciant cu amănuntul are propriii săi oameni IT foarte cool, dar sunt departe de a înlocui routerele și de a urmări cablurile.Ce facem
- Lucrăm la solicitări - bilete și apeluri de panică.
- Facem prevenire.
- Urmăm recomandările vânzătorilor de hardware, de exemplu, cu privire la condițiile de întreținere.
- Ne conectăm la monitorizarea clientului și eliminăm date de la acesta pentru a călători în caz de incidente.
Prima modalitate - verificări simple - este doar o mașină care trimite ping la toate nodurile din rețea și se asigură că acestea răspund corect. O astfel de implementare nu necesită deloc modificări sau modificări cosmetice minime în rețeaua clientului. De regulă, într-un caz foarte simplu, instalăm Zabbix direct la noi înșine într-unul dintre centrele de date (din fericire, avem două dintre ele în biroul CROC de pe Volochaevskaya). Într-una mai complexă, de exemplu, dacă utilizați propria rețea securizată - la una dintre mașinile din centrul de date al clientului:
Zabbix poate fi folosit mai complicat, de exemplu, are agenți care sunt instalați pe nodurile * nix și win și arată monitorizarea sistemului, precum și modul de verificare extern (cu suport pentru protocolul SNMP). Cu toate acestea, dacă o afacere are nevoie de ceva similar, atunci fie are deja propria lor monitorizare, fie se alege o soluție mai bogată funcțional. Desigur, acesta nu mai este open source și costă bani, dar chiar și un inventar exact banal bate deja costurile cu aproximativ o treime.
Facem și asta, dar aceasta este povestea colegilor. Aici au trimis câteva capturi de ecran ale Infosim:
Sunt un operator avatar, așa că vă voi spune mai multe despre munca mea.
Cum arată un incident tipic?
În fața noastră sunt ecrane cu următoarea stare generală:
Pe acest site, Zabbix colectează destul de multe informații pentru noi: număr de piesă, număr de serie, utilizarea procesorului, descrierea dispozitivului, disponibilitatea interfețelor etc. Toate informațiile necesare sunt disponibile din această interfață.
Un incident obișnuit începe de obicei cu faptul că unul dintre canalele care duc spre, de exemplu, magazinul clientului (din care are 200-300 de bucăți în toată țara) cade. Retailul este acum bine dezvoltat, nu ca acum șapte ani, așa că box office-ul va continua să funcționeze - există două canale.
Luăm telefoanele și facem cel puțin trei apeluri: către furnizor, centrală și oamenii de la fața locului („Da, am încărcat fitinguri aici, s-a atins cablul cuiva... A, al tău? Ei bine, e bine că am găsit-o").
De regulă, fără monitorizare, înainte de escaladare ar trece ore sau zile - aceleași canale de rezervă nu sunt întotdeauna verificate. Știm imediat și plecăm imediat. Dacă există informații suplimentare, altele decât ping-uri (de exemplu, un model al unei piese de fier buggy), completăm imediat inginerul de teren cu piesele necesare. Mai departe, deja pe loc.
Al doilea cel mai frecvent apel obișnuit este defectarea unuia dintre terminalele pentru utilizatori, de exemplu, un telefon DECT sau un router Wi-Fi care a distribuit rețeaua la birou. Aici aflăm despre problemă din monitorizare și aproape imediat primim un apel cu detalii. Uneori apelul nu adaugă nimic nou („Ridic telefonul, ceva nu sună”), uneori este foarte util („L-am scăpat de la masă”). Este clar că, în al doilea caz, aceasta nu este clar o întrerupere de linie.
Echipamentele din Moscova sunt luate din depozitele noastre de rezervă, avem mai multe tipuri:
Clienții au de obicei propriile stocuri de componente care se defectează frecvent - telefoane de birou, surse de alimentare, ventilatoare și așa mai departe. Dacă trebuie să livrați ceva care nu este la locul lui, nu la Moscova, de obicei mergem singuri (din cauza instalării). De exemplu, am avut o excursie de noapte la Nijni Tagil.
Dacă clientul are propria monitorizare, poate încărca date către noi. Uneori implementăm Zabbix în modul de sondare, doar pentru a asigura transparența și controlul SLA (acest lucru este gratuit și pentru client). Nu instalăm senzori suplimentari (asta se face de către colegi care asigură continuitatea proceselor de producție), dar ne putem conecta la aceștia dacă protocoalele nu sunt exotice.
În general, nu atingem infrastructura clientului, ci doar o susținem așa cum este.
Din experiență pot spune că ultimii zece clienți au trecut la suport extern datorită faptului că suntem foarte previzibili din punct de vedere al costurilor. Bugetare clară, management bun de caz, raport pentru fiecare cerere, SLA, rapoarte de echipamente, întreținere preventivă. În mod ideal, desigur, suntem pentru CIO al unui client precum curățenii – venim și facem asta, totul este curat, nu distragem atenția.
Un alt lucru demn de remarcat este că, în unele companii mari, inventarul devine o problemă reală și, uneori, suntem atrași doar de a le realiza. În plus, facem stocarea configurațiilor și gestionarea acestora, ceea ce este convenabil pentru diferite relocari și reconectări. Dar, din nou, în cazurile dificile, nu sunt nici eu - avem o echipă specială care transportă centre de date.
Și încă un punct important: departamentul nostru nu se ocupă de infrastructura critică. Totul din centrele de date și tot ce este bancar-operator de asigurări, plus sistemele de bază de retail - aceasta este o echipă X. Aici sunt băieții.
Mai practic
Multe dispozitive moderne sunt capabile să ofere o mulțime de informații de service. De exemplu, imprimantele de rețea sunt foarte ușor de monitorizat nivelul de toner din cartuș. Poți conta pe perioada de înlocuire în avans, plus să ai o notificare de 5-10% (dacă biroul începe brusc să scrie cu furie nu în programul standard) - și să trimiți imediat un enikey înainte ca departamentul de contabilitate să intre în panică.De foarte multe ori ni se iau statisticile anuale, ceea ce se face de acelasi sistem de monitorizare plus noi. În cazul Zabbix, aceasta este o simplă planificare a costurilor și înțelegerea a ceea ce a mers prost, iar în cazul Infosim, este, de asemenea, material pentru calcularea scalării pentru un an, încărcarea administratorilor și tot felul de alte lucruri. În statistică este consum de energie - în ultimul an aproape toată lumea a început să-l întrebe, se pare că pentru a împrăștia costurile interne între departamente.
Uneori se obțin adevărate salvări eroice. Asemenea situații sunt foarte rare, dar din câte îmi amintesc anul acesta, am văzut în jurul orei 3 dimineața că temperatura a urcat la 55 de grade la comutatorul Cisco. În camera de server îndepărtată erau aparate de aer condiționat „prostice” fără monitorizare și au eșuat. Am sunat imediat un inginer de răcire (nu al nostru) și am chemat administratorul clientului de serviciu. A pus niște servicii necritice și a păstrat camera serverelor de la doborârea termică până a sosit tipul cu un aparat de aer condiționat mobil, iar apoi au fost reparate cele obișnuite.
Polycoms și alte echipamente scumpe de videoconferință monitorizează foarte bine nivelul de încărcare a bateriei înainte de conferințe, ceea ce este de asemenea important.
Toată lumea are nevoie de monitorizare și diagnosticare. De regulă, este lung și dificil de implementat fără experiență: sistemele sunt fie extrem de simple și preconfigurate, fie de dimensiunea unui portavion și cu o grămadă de rapoarte standard. Ascuțirea cu un fișier pentru companie, inventarea implementării sarcinilor acestora pentru departamentul IT intern și afișarea informațiilor de care au cel mai mult nevoie, plus păstrarea la zi a întregului istoric este o greșeală dacă nu există experiență de implementare. Când lucrăm cu sisteme de monitorizare, alegem mijlocul de aur între soluțiile gratuite și cele de top - de regulă, nu cei mai populari și „groși” furnizori, dar rezolvând clar problema.
Odată a existat un tratament destul de atipic. Clientul a trebuit să dea routerul unora dintre diviziile sale separate și exact conform inventarului. Routerul avea un modul cu numărul de serie specificat. Când routerul a început să se pregătească pentru drum, s-a dovedit că acest modul lipsea. Și nimeni nu o poate găsi. Problema este ușor agravată de faptul că inginerul care a lucrat anul trecut cu această ramură este deja pensionar și a plecat să locuiască cu nepoții săi în alt oraș. Ne-au contactat și ne-au cerut să ne uităm. Din fericire, hardware-ul a dat rapoarte privind numerele de serie, iar Infosim a făcut un inventar, așa că în câteva minute am găsit acest modul în infrastructură și am descris topologia. Fugarul a fost urmărit prin cablu - se afla într-o altă cameră de server într-un dulap. Istoria mișcării a arătat că a ajuns acolo după eșecul unui modul similar.
Un cadru dintr-un lungmetraj despre Hottabych, care descrie cu exactitate atitudinea populației față de camere
O mulțime de incidente cu camera. Odată, 3 camere au eșuat simultan. Rupere cablu într-una din secțiuni. Instalatorul a suflat unul nou în ondulat, două dintre cele trei camere s-au ridicat după o serie de șamanism. Iar al treilea nu este. Mai mult, nu este deloc clar unde se află. Ridic fluxul video - ultimele cadre chiar înainte de toamnă - 4 dimineața, trei bărbați în eșarfe pe față urcă, ceva strălucitor dedesubt, camera tremură mult, cade.
Odată ce am instalat camera, care ar trebui să se concentreze pe „iepurii de câmp” care se cațără peste gard. În timpul conducerii, ne-am gândit cum am desemna punctul în care ar trebui să apară intrusul. Nu a fost de folos - în cele 15 minute în care am fost acolo, 30 de persoane au intrat în obiect doar în punctul de care aveam nevoie. Masă dreaptă.
După cum am dat deja un exemplu mai sus, povestea despre clădirea demolată nu este o glumă. Odată ce legătura către echipament a dispărut. Pe loc - nu există nici un pavilion pe unde a trecut cuprul. Pavilionul a fost demolat, cablul a dispărut. Am văzut că routerul era mort. Instalatorul a sosit, a început să caute - iar distanța dintre noduri este de câțiva kilometri. Are un tester Vipnet în setul său, standardul - a sunat de la un conector, a sunat de la altul - s-a dus să caute. De obicei, problema este imediat vizibilă.
Urmărirea cablului: aceasta este optică ondulată, o continuare a poveștii din partea de sus a postării despre nod. Aici, până la urmă, pe lângă instalarea absolut uimitoare, problema era că cablul se îndepărtase de monturi. Aici urcați pe toți și pe toate și slăbiți structurile metalice. Aproximativ cinci mii de reprezentant al proletariatului a spart optica.
La o unitate, toate nodurile au fost oprite aproximativ o dată pe săptămână.Și în același timp. Căutăm un model de ceva timp. Programul de instalare a găsit următoarele:
- Problema apare întotdeauna în tura aceleiași persoane.
- Se deosebește de ceilalți prin faptul că poartă o haină foarte grea.
- O mașină automată este montată în spatele unui cuier.
- Cineva a luat capacul mașinii cu mult timp în urmă, în timpuri preistorice.
- Când această tovarășă vine la clădire, el își închide hainele, iar ea oprește aparatele.
- Le pornește imediat.
Echipamentul a fost oprit la una și aceeași oră, la aceeași oră, noaptea. S-a dovedit că meșterii locali s-au conectat la sursa noastră de alimentare, au scos un prelungitor și au înfipt acolo un fierbător și o sobă electrică. Când aceste dispozitive funcționează simultan, întregul pavilion este dezactivat.
Într-unul dintre magazinele țării noastre vaste, întreaga rețea se prăbuși constant odată cu închiderea turei. Instalatorul a văzut că toată puterea a fost adusă la linia de iluminat. De îndată ce iluminatul de deasupra holului (care consumă multă energie) este stins în magazin, toate echipamentele de rețea sunt oprite.
A existat un caz în care portarul a întrerupt cablul cu o lopată.
Adesea vedem doar cupru culcat cu o ondulare ruptă. Odată, între două ateliere, meșterii locali au trimis pur și simplu un cablu torsadat fără nicio protecție.
Departe de civilizație, angajații se plâng adesea că sunt expuși echipamentelor „noastre”. Panourile de distribuție din unele locații îndepărtate pot fi în aceeași cameră cu persoana de serviciu. În consecință, de câteva ori am dat peste bunici dăunătoare, care, prin cârlig sau prin escroc, le-au oprit la începutul turei.
Un alt oraș îndepărtat a atârnat un mop pe optică. Au rupt ondularea de pe perete, au început să o folosească ca elemente de fixare pentru echipamente.
În acest caz, există clar probleme cu alimentația.
Ce poate face monitorizarea „mare”.
Voi vorbi pe scurt despre capacitățile sistemelor mai serioase, folosind exemplul instalărilor Infosim. Există 4 soluții combinate într-o singură platformă:- Managementul defecțiunilor - controlul defecțiunilor și corelarea evenimentelor.
- Managementul performantei.
- Inventar și descoperire automată a topologiei.
- Managementul configurației.
Separat, despre inventar. Modulul nu numai că arată lista, dar construiește și topologia în sine (cel puțin în 95% din cazuri încearcă și reușește). De asemenea, vă permite să aveți la îndemână o bază de date actualizată cu echipamente IT uzate și inactive (rețea, echipamente server etc.), pentru a înlocui la timp echipamentele învechite (EOS/EOL). În general, este convenabil pentru întreprinderile mari, dar în întreprinderile mici, o mare parte din acest lucru se face manual.
Exemple de rapoarte:
- Rapoarte pe tip de OS, firmware, modele și producători de echipamente;
- Raportați numărul de porturi libere pe fiecare switch din rețea / după producătorul selectat / după model / după subrețea etc.;
- Raportare asupra dispozitivelor nou adăugate pentru o perioadă specificată;
- Avertisment de toner scăzut al imprimantei;
- Evaluarea caracterului adecvat al canalului de comunicație pentru trafic sensibil la întârzieri și pierderi, metode active și pasive;
- Urmărirea calității și disponibilității canalelor de comunicații (SLA) - generarea de rapoarte privind calitatea canalelor de comunicații, defalcate pe operatori de telecomunicații;
- Funcționalitatea de control al eșecurilor și corelarea evenimentelor este implementată prin mecanismul de analiză a cauzei fundamentale (fără a fi nevoie ca administratorii să scrie reguli) și mecanismul Alarm States Machine. Root-Cause Analysis este o analiză a cauzei fundamentale a unui accident bazată pe următoarele proceduri: 1. detectarea și localizarea automată a locului de defecțiune; 2. reducerea numărului de evenimente de urgență la o singură cheie; 3. identificarea consecințelor unui eșec – cine și ce a fost afectat de eșec.
Stablenet - Agent încorporat (SNEA) - un computer puțin mai mare decât un pachet de țigări.
Instalarea se realizează în ATM-uri sau în segmente de rețea dedicate unde este necesară testarea accesibilității. Cu ajutorul lor, se efectuează testarea încărcării.
Monitorizare cloud
Un alt model de instalare este SaaS în cloud. Realizat pentru un singur client global (o companie cu un ciclu de producție continuu cu o geografie de distribuție din Europa în Siberia).Zeci de facilități, inclusiv fabrici și depozite pentru produse finite. Dacă canalele lor au căzut și sprijinul lor a fost efectuat de la birourile externe, atunci au început întârzierile de expediere, care, de-a lungul valului, au dus la pierderi suplimentare. Toate lucrările au fost făcute la cerere și s-a cheltuit mult timp pentru investigarea incidentului.
Am configurat monitorizarea special pentru ei, apoi am terminat-o pe o serie de site-uri în funcție de specificul rutării și hardware-ului lor. Toate acestea au fost făcute în cloud-ul CROC. Au finalizat și livrat proiectul foarte repede.
Rezultatul este:
- Datorită transferului parțial al managementului infrastructurii de rețea, a fost posibilă optimizarea a cel puțin 50%. Inaccesibilitatea echipamentelor, încărcarea canalului, depășirea parametrilor recomandați de producător: toate acestea sunt reparate în 5-10 minute, diagnosticate și eliminate în decurs de o oră.
- Atunci când primește un serviciu din cloud, clientul transferă costurile de capital ale implementării sistemului său de monitorizare a rețelei în costuri de operare pentru o taxă de abonament pentru serviciul nostru, la care poate fi renunțată în orice moment.
Avantajul cloud-ului este că în decizia noastră stăm, parcă, deasupra rețelei lor și putem privi tot ce se întâmplă mai obiectiv. La acel moment, dacă am fi în interiorul rețelei, am vedea poza doar până la nodul de defecțiune, iar ce se întâmplă în spatele ei, nu am mai ști.
Câteva ultime poze
Acesta este „puzzle-ul de dimineață”:
Și aceasta este comoara pe care am găsit-o:
Iată ce era în piept:
Și în sfârșit, despre cea mai amuzantă ieșire. Am fost odată la o unitate de vânzare cu amănuntul.
Acolo s-au întâmplat următoarele: mai întâi, a început să picure de pe acoperiș pe tavanul fals. Apoi s-a format în tavanul fals un lac, care a erodat și a zdrobit una dintre plăci. Drept urmare, toate acestea au țâșnit la electrician. Apoi nu știu exact ce s-a întâmplat, dar undeva în camera alăturată a fost un scurtcircuit și a început un incendiu. Mai întâi au funcționat stingătoarele cu pulbere, iar apoi au sosit pompierii care au umplut totul cu spumă. Am ajuns dupa ei pentru demontare. Trebuie să spun că 2960 tsiska a avut ideea după toate acestea - am putut să ridic configurația și să trimit dispozitivul pentru reparație.
Încă o dată, în timpul declanșării sistemului de pulbere, Tsiskovsky 3745 într-un borcan a fost aproape complet umplut cu pulbere. Toate interfețele erau pline - 2 x 48 porturi. Trebuia inclus pe loc. Și-au amintit ultimul caz, au decis să încerce să elimine configurațiile „fierbinte”, l-au scuturat, l-au curățat cât au putut de bine. L-am pornit - la început dispozitivul a spus „pff” și ne-a strănutat cu un jet mare de pulbere. Și apoi a bubuit și s-a ridicat.
cerere de ecou
O cerere de ecou (ping) este un instrument de diagnosticare folosit pentru a afla dacă o anumită gazdă este accesibilă într-o rețea IP. Solicitarea ecou se face folosind protocolul ICMP (Internet Control Message Protocol). Acest protocol este folosit pentru a trimite o cerere de ecou gazdei care este verificată. Gazda trebuie configurată să accepte pachete ICMP.
Examinare
prin cerere de ecou
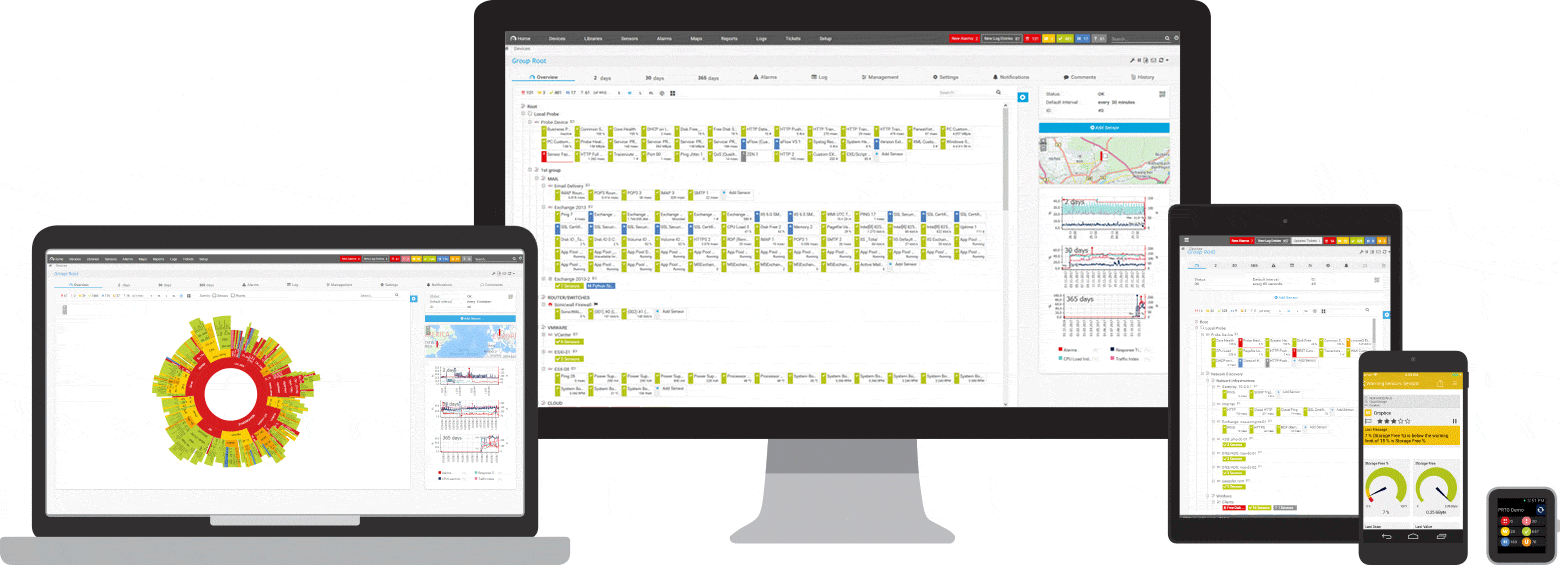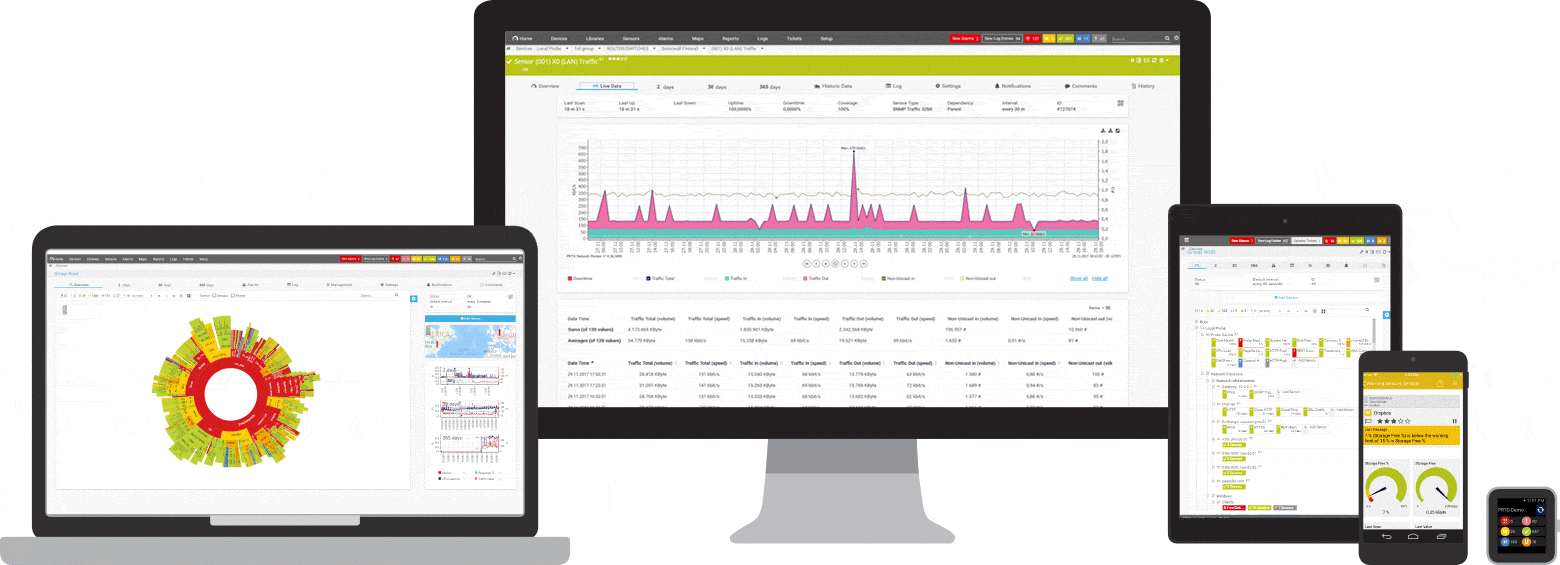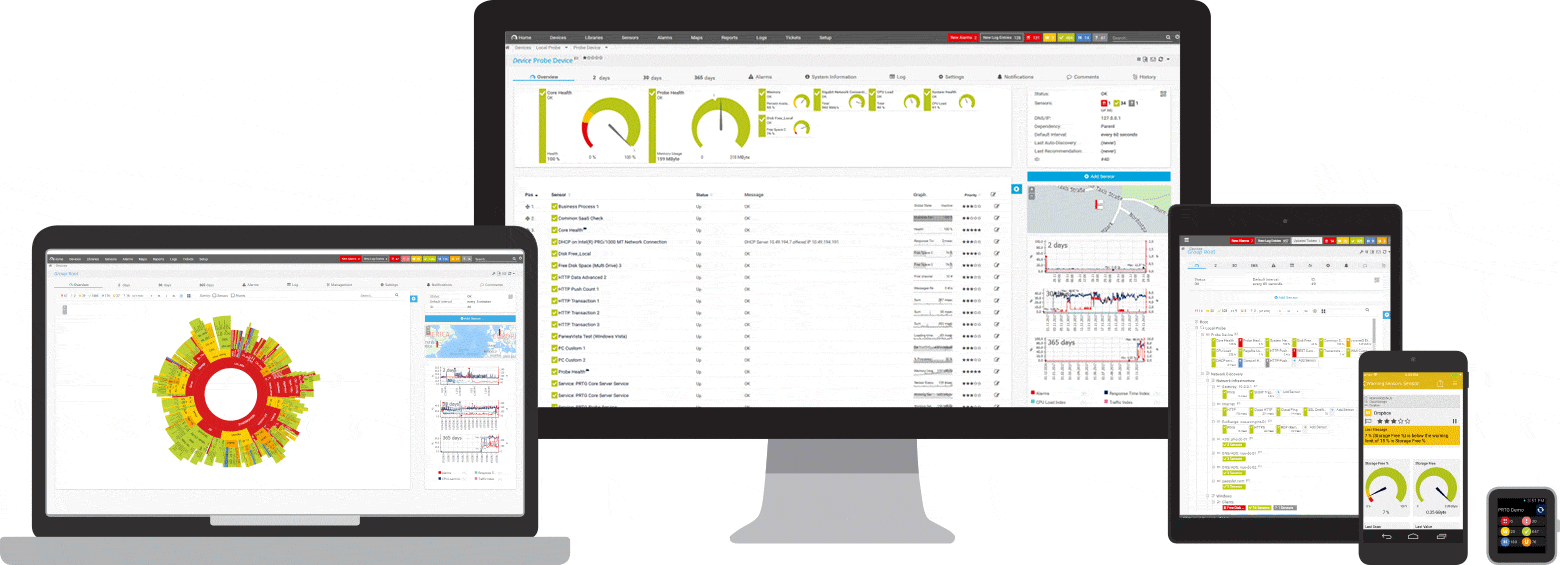
PRTG este un instrument de monitorizare ping și rețea pentru Windows. Este compatibil cu toate sistemele majore Windows, inclusiv Windows Server 2012 R2 și Windows 10.
PRTG este un instrument puternic pentru întreaga rețea. Pentru servere, routere, comutatoare, timp de funcționare și conexiuni la cloud, PRTG ține evidența tuturor, astfel încât să puteți elimina bătălia de la administrare. Senzorul ping, precum și senzorii SNMP , NetFlow și sniffing de pachete sunt utilizați pentru a colecta informații detaliate despre disponibilitatea rețelei și volumul de lucru.
PRTG are un sistem de alarmă încorporat personalizabil care vă anunță rapid despre probleme. Senzorul ping este configurat ca senzor principal pentru dispozitivele de rețea. Dacă acest senzor nu reușește, toți ceilalți senzori de pe dispozitiv sunt puși în modul de repaus. Aceasta înseamnă că, în loc de un flux de mesaje de alertă, veți primi o singură notificare.
Oricând doriți, puteți afișa o prezentare generală rapidă pe tabloul de bord PRTG. Vei vedea imediat dacă totul este în ordine. Tabloul de bord este personalizabil pentru a se potrivi nevoilor dumneavoastră specifice. Departe de locul de muncă, cum ar fi atunci când lucrați într-o cameră de server, accesul la PRTG este posibil printr-o aplicație pentru smartphone și nu veți rata niciodată un singur eveniment.
Monitorizarea inițială este configurată imediat în timpul instalării. Acest lucru este posibil datorită funcției de auto-descoperire: PRTG ping adresele IP private și creează automat senzori pentru dispozitivele disponibile. Când deschideți PRTG pentru prima dată, puteți verifica imediat disponibilitatea rețelei dvs.
Programul PRTG are un model de licențiere transparent. Puteți testa PRTG gratuit. Senzorul de cerere ecou și funcția de alarmă sunt de asemenea incluse în versiunea gratuită și au o perioadă de utilizare nelimitată. Dacă compania sau rețeaua dvs. are nevoie de mai multe funcții, este ușor să vă actualizați licența.
Capturi de ecran
O scurtă introducere în PRTG: Ping Monitoring



Senzorii dvs. de ping sunt vizibili
- chiar și în deplasare
PRTG se instalează în câteva minute și este compatibil cu majoritatea dispozitivelor mobile.
PRTG controlează aceștia și mulți alți producători și aplicații pentru dvs
Trei senzori PRTG pentru monitorizarea ping-ului
Senzor
cereri de ecou
din nor
Senzorul Cloud Ping folosește PRTG Cloud pentru a măsura timpul necesar pentru a vă trimite ping la rețea din diferite locații din lume. Acest senzor vă permite să vedeți disponibilitatea rețelei dvs. în Asia, Europa și America. În special, acest indicator este foarte important pentru companiile internaționale. .
Prin achiziționarea software-ului PRTG, veți primi asistență completă gratuită. Sarcina noastră este să vă rezolvăm problemele cât mai repede posibil! În special pentru aceasta, împreună cu alte materiale, am pregătit videoclipuri de instruire și un ghid cuprinzător. Ne propunem să răspundem la toate biletele de asistență în termen de 24 de ore (în zilele lucrătoare). Veți găsi răspunsuri la multe întrebări în baza noastră de cunoștințe. De exemplu, interogarea de căutare „monitorizare ping” returnează 700 de rezultate. Câteva exemple:
„Am nevoie de un senzor ping care să colecteze informații doar despre disponibilitatea dispozitivului, fără a-i schimba starea. Este posibil?"
„Pot construi un senzor de cerere de ecou invers?”

„Cu PRTG, ne simțim mult mai confortabil știind că sistemele noastre sunt monitorizate continuu.”
Markus Puke, administrator de rețea, clinica Schüchtermann (Germania)
- Versiunea completă a PRTG timp de 30 de zile
- După 30 de zile - versiune gratuită
- Pentru versiunea extinsă - licență comercială

| Software de monitorizare a rețelei - versiunea 19.2.50.2842 (15 mai 2019) | |
|
Gazduire |
Versiune cloud disponibilă și (PRTG în cloud) |
Limbi |
Engleză, germană, rusă, spaniolă, franceză, portugheză, olandeză, japoneză și chineză simplificată |
Preturi |
Gratuit până la 100 de senzori (prețuri) |
Monitorizare cuprinzătoare |
Dispozitive de rețea, lățime de bandă, servere, aplicații, medii virtuale, sisteme la distanță, IoT și multe altele. |
Furnizori și aplicații acceptate |
Monitorizarea rețelei și ping cu PRTG: trei studii de caz practice
200.000 de administratori din întreaga lume se bazează pe programul PRTG. Acești administratori pot proveni din industrii diferite, dar toți au un lucru în comun - dorința de a asigura și îmbunătăți disponibilitatea și performanța rețelelor lor. Trei cazuri de utilizare:

aeroportul din Zurich
Aeroportul Zurich este cel mai mare aeroport din Elveția, așa că este deosebit de important ca toate sistemele sale electronice să funcționeze fără probleme. Pentru a face acest lucru posibil, departamentul IT a implementat software-ul PRTG Network Monitor de la Paessler AG. Cu peste 4.500 de senzori, acest instrument asigură că problemele sunt detectate și rezolvate imediat de către echipa IT. În trecut, departamentul IT folosea o varietate de programe de monitorizare. Dar, în cele din urmă, conducerea a concluzionat că software-ul nu era potrivit pentru monitorizarea specializată de către personalul de operare și întreținere. Exemplu de utilizare.

Universitatea Bauhaus, Weimar
Sistemele IT ale Universității Bauhaus din Weimar sunt folosite de 5.000 de studenți și 400 de angajați. În trecut, pentru monitorizarea rețelei universitare era folosită o soluție izolată bazată pe Nagios. Sistemul era depășit din punct de vedere tehnic și nu era capabil să răspundă nevoilor infrastructurii IT a instituției de învățământ. Modernizările infrastructurii ar fi extrem de costisitoare. În schimb, universitatea a apelat la noi soluții de monitorizare a rețelei. Directorii IT doreau un produs software cuprinzător care să fie ușor de utilizat, ușor de instalat și rentabil. De aceea au ales PRTG. Exemplu de utilizare.

Utilități publice ale orașului Frankenthal
Puțin mai mult de 200 de angajați ai utilităților publice din orașul Frankenthal sunt responsabili pentru furnizarea de energie electrică, gaz și apă consumatorilor privați și organizațiilor. Organizația, cu toate clădirile sale, depinde și de o infrastructură distribuită local, care constă din aproximativ 80 de servere și 200 de dispozitive conectate. Directorii IT ai Frankenthal căutau software la prețuri accesibile pentru a satisface nevoile lor specifice. În primul rând, IT a creat o versiune de încercare gratuită a PRTG. Utilitățile publice ale lui Frankenthal folosesc în prezent aproximativ 1.500 de senzori pentru a monitoriza, printre altele, piscinele publice. Exemplu de utilizare.

Sfaturi practice. Spune-mi, Greg, ai recomandări pentru monitorizarea ping-urilor?
„Senzorii de pingback sunt probabil cele mai importante elemente ale monitorizării rețelei. Acestea trebuie configurate corect, mai ales având în vedere conexiunile dvs. Dacă, de exemplu, monitorizați funcționarea unei mașini virtuale, atunci este util să plasați un senzor ping în conexiunea la gazda acesteia. Dacă un nod eșuează, nu veți primi o notificare pentru fiecare mașină virtuală conectată la acesta. În plus, senzorii de ping pot fi indicatori buni că calea rețelei către gazdă sau internet funcționează corect, mai ales în scenariile de înaltă disponibilitate sau failover.”
Greg Campion, administrator de sistem, PAESSLER AG