Ping monitorovací softvér. Monitorovanie siete: ako zabezpečujeme, aby všetky uzly fungovali pre veľké spoločnosti
Robustný nástroj na monitorovanie pingu na automatickú kontrolu pripojenia k hostiteľom siete. Pravidelným pingom monitoruje sieťové pripojenia a upozorní vás na zistené vzostupy/doly. EMCO Ping Monitor tiež poskytuje štatistické informácie o pripojení, vrátane doby prevádzkyschopnosti, výpadkov, neúspešných pingov atď. Môžete jednoducho rozšíriť funkčnosť a nakonfigurovať EMCO Ping Monitor na vykonávanie vlastných príkazov alebo spúšťanie aplikácií pri strate alebo obnovení pripojenia.
Čo je EMCO Ping Monitor?
EMCO Ping Monitor môže pracovať v režime 24/7 a sledovať stavy pripojenia jedného alebo viacerých hostiteľov. Aplikácia analyzuje odpovede ping, aby zistila výpadky pripojenia a nahlásila štatistiky pripojenia. Dokáže automaticky zistiť výpadky pripojenia a zobraziť bubliny na paneli Windows, prehrať zvuky a odoslať e-mailové upozornenia. Môže tiež generovať správy a odosielať ich e-mailom alebo uložiť ako súbory PDF alebo HTML.
Program vám umožňuje získať informácie o stave všetkých hostiteľov, skontrolovať podrobné štatistiky vybraného hostiteľa a porovnať výkon rôznych hostiteľov. Program ukladá zozbierané pingové údaje do databázy, takže si môžete skontrolovať štatistiky za zvolené časové obdobie. Dostupné informácie zahŕňajú min/max/priemerný čas pingu, odchýlku pingu, zoznam výpadkov pripojenia atď. Tieto informácie môžu byť reprezentované ako mriežkové dáta a grafy.
EMCO Ping Monitor: Ako to funguje?
EMCO Ping Monitor možno použiť na vykonávanie monitorovania pingom iba niekoľkých hostiteľov alebo tisícok hostiteľov. Všetci hostitelia sú monitorovaní v reálnom čase pomocou vyhradených pracovných vlákien, takže pre každého hostiteľa môžete získať štatistiky a upozornenia na zmeny stavu pripojenia v reálnom čase. Program nemá špeciálne požiadavky na hardvér – na typickom modernom PC môžete monitorovať niekoľko tisíc hostiteľov.
Program používa ping na detekciu výpadkov pripojenia. Ak zlyhá niekoľko pingov v režime raw - ohlási výpadok a upozorní vás na problém. Keď je pripojenie nadviazané a začnú prechádzať pingy - program zistí koniec výpadku a upozorní vás na to. Môžete prispôsobiť výpadok a obnoviť podmienky detekcie a tiež upozornenia používané programom.
Porovnajte funkcie a vyberte edíciu
Program je dostupný v troch vydaniach s rôznou sadou funkcií.
Porovnať vydania
Bezplatná edícia umožňuje vykonávať ping monitorovanie až 5 hostiteľov. Nepovoľuje žiadnu špecifickú konfiguráciu pre hostiteľov. Funguje ako program Windows, takže monitorovanie sa zastaví, ak zatvoríte používateľské rozhranie alebo sa odhlásite zo systému Windows.
Zadarmo na osobné a komerčné použitie
Profesionálne vydanie
Verzia Professional umožňuje monitorovanie až 250 hostiteľov súčasne. Každý hostiteľ môže mať vlastnú konfiguráciu, ako napríklad upozornenie na príjemcov e-mailu alebo vlastné akcie, ktoré sa majú vykonať pri strate spojenia a udalostiach obnovenia. Funguje ako služba systému Windows, takže monitorovanie pokračuje, aj keď zatvoríte používateľské rozhranie alebo sa odhlásite zo systému Windows.
Enterprise Edition
Vydanie Enterprise nemá obmedzenia na počet monitorovaných hostiteľov. Na modernom PC je možné monitorovať 2500+ hostiteľov v závislosti od hardvérovej konfigurácie.
Toto vydanie obsahuje všetky dostupné funkcie a funguje ako klient/server. Server funguje ako služba Windows na zabezpečenie monitorovania pingu v režime 24/7. Klient je program Windows, ktorý sa môže pripojiť k serveru bežiacemu na lokálnom počítači alebo k vzdialenému serveru prostredníctvom siete LAN alebo internetu. Viacerí klienti sa môžu pripojiť k rovnakému serveru a pracovať súčasne.
Toto vydanie obsahuje aj webové správy, ktoré umožňujú vzdialenú kontrolu štatistík monitorovania hostiteľa vo webovom prehliadači.
Hlavné funkcie EMCO Ping Monitor
Monitorovanie Ping viacerých hostiteľov
Aplikácia môže monitorovať viacero hostiteľov súčasne. Bezplatná edícia aplikácie umožňuje monitorovanie až piatich hostiteľov; edícia Professional nemá žiadne obmedzenie na počet monitorovaných počítačov Monitorovanie každého hostiteľa funguje nezávisle od ostatných počítačov Z moderného počítača môžete sledovať desiatky tisíc hostiteľov.
Detekcia výpadkov pripojenia
Aplikácia posiela ICMP ping echo požiadavky a analyzuje ping echo odpovede na monitorovanie stavu pripojenia v režime 24/7. Ak prednastavený počet pingov zlyhá v rade, aplikácia zistí výpadok pripojenia a upozorní vás na problém. Aplikácia sleduje všetky výpadky, takže môžete vidieť, kedy bol hostiteľ offline.
Analýza kvality pripojenia
Keď aplikácia odošle ping monitorovanému hostiteľovi, uloží a zhromažďuje údaje o každom pingu, takže môžete získať informácie o minimálnych, maximálnych a priemerných časoch odozvy ping a odchýlke odozvy ping od priemeru za akékoľvek vykazované obdobie. To vám umožní odhadnúť kvalitu sieťového pripojenia.
Flexibilné upozornenia
Ak chcete dostávať upozornenia o strate pripojenia, obnovení pripojenia a iných udalostiach, ktoré aplikácia zistila, môžete aplikáciu nakonfigurovať tak, aby odosielala upozornenia e-mailom, prehrávala zvuky a zobrazovala bubliny na paneli Windows. Aplikácia môže odoslať jedno upozornenie akéhokoľvek typu alebo viackrát zopakovať upozornenia.
Grafy a prehľady
Všetky štatistické informácie zhromaždené aplikáciou možno vizuálne znázorniť pomocou grafov. Môžete vidieť ping a štatistiky dostupnosti pre jedného hostiteľa a porovnať výkon viacerých hostiteľov v grafoch. Aplikácia môže automaticky pravidelne generovať správy v rôznych formátoch, ktoré reprezentujú štatistiky hostiteľa.
Vlastné akcie
Aplikáciu môžete integrovať s externým softvérom spustením externých skriptov alebo spustiteľných súborov pri strate alebo obnovení spojenia alebo v prípade iných udalostí. Môžete napríklad nakonfigurovať aplikáciu tak, aby spúšťala externý nástroj príkazového riadka na odosielanie SMS upozornení o akýchkoľvek zmenách v stavoch hostiteľa.
Podľa vzhľadu tejto optiky, prechádzajúcej lesom ku kolektoru, môžeme usúdiť, že inštalatér trochu nedodržal technológiu. Mount na fotografii tiež naznačuje, že ide pravdepodobne o námorníka - morský uzol.
Som v zdravotníckom tíme fyzickej siete, inými slovami technická podpora, ktorá je zodpovedná za to, aby kontrolky na smerovačoch blikali tak, ako majú. Máme pod krídlami rôzne veľké spoločnosti s infraštruktúrou po celej krajine. Nelezieme do ich biznisu, našou úlohou je zabezpečiť, aby sieť fungovala na fyzickej úrovni a premávka prebiehala tak, ako má.
Všeobecným zmyslom práce je neustále dotazovanie uzlov, odstraňovanie telemetrie, testovacie chody (napríklad kontrola nastavení na nájdenie zraniteľností), zabezpečenie zdravia, sledovanie aplikácií, návštevnosti. Niekedy zásoby a iné zvrátenosti.
Poviem vám o tom, ako je to organizované a pár príbehov z výletov.
Ako to zvyčajne býva
Náš tím sedí v kancelárii v Moskve a vykonáva sieťovú telemetriu. V skutočnosti sú to neustále pingy uzlov, ako aj prijímanie monitorovacích údajov, ak je hardvér inteligentný. Najčastejšou situáciou je, že ping neprejde niekoľkokrát za sebou. Napríklad v 80 % prípadov maloobchodného reťazca ide o výpadok elektriny, takže keď vidíme tento obrázok, robíme nasledovné:- Najprv zavoláme poskytovateľovi o nehodách
- Potom - do elektrárne o odstávke
- Potom sa snažíme nadviazať spojenie s niekým v zariadení (nie vždy je to možné, napr. o 2:00)
- A nakoniec, ak vyššie uvedené nepomohlo do 5-10 minút, odídeme alebo pošleme „avatara“ - zmluvného inžiniera, ktorý sedí niekde v Iževsku alebo Vladivostoku, ak je tam problém.
- S „avatarom“ udržiavame neustály kontakt a „vedieme“ ho infraštruktúrou – máme senzory a servisné manuály, on má kliešte.
- Potom nám inžinier pošle správu s fotografiou, čo to bolo.
Dialóg niekedy vyzerá takto:
- Takže medzi budovami číslo 4 a 5 sa stratilo spojenie. Skontrolujte router v piatej.
- Objednávka vrátane. Nie je tam žiadne spojenie.
- Dobre, choďte po kábli do štvrtej budovy, tam je ďalší uzol.
-... Oppa!
- Čo sa stalo?
- Tu bol zbúraný 4. dom.
- Čo??
- K správe prikladám fotografiu. Nemôžem obnoviť dom v SLA.

Ale častejšie sa ukáže, že nájde prestávku a obnoví kanál.
Približne 60% výjazdov je „v mlieku“, pretože buď je prerušené napájanie (lopatou, majstrom, votrelcami), alebo poskytovateľ nevie o jeho poruche, alebo je krátkodobý problém odstránený skôr, ako inštalatér prichádza. Sú však chvíle, keď sa o probléme dozvieme skôr ako používatelia a skôr ako IT služby zákazníka, a komunikujeme riešenie skôr, než si vôbec uvedomia, že sa niečo stalo. Najčastejšie k takýmto situáciám dochádza v noci, keď je aktivita v zákazníckych spoločnostiach nízka.
Kto to potrebuje a prečo
Každá veľká firma má spravidla svoje IT oddelenie, ktoré jasne rozumie špecifikám a úlohám. V stredných a veľkých podnikoch je práca „enikeevov“ a sieťových inžinierov často outsourcovaná. Je to len výhodné a pohodlné. Napríklad jeden maloobchodník má svojich vlastných skvelých IT ľudí, no ani zďaleka nenahrádzajú smerovače a sledujú káble.Čo robíme
- Pracujeme na žiadostiach - lístkoch a panikach.
- Robíme prevenciu.
- Riadime sa odporúčaniami predajcov hardvéru, napríklad čo sa týka podmienok údržby.
- Pripájame sa k monitorovaniu zákazníka a odstraňujeme z neho údaje, aby sme mohli v prípade incidentov cestovať.
Prvý spôsob – jednoduché kontroly – je len stroj, ktorý pingne všetky uzly v sieti a uistí sa, že reagujú správne. Takáto implementácia si nevyžaduje žiadne zmeny alebo minimálne kozmetické úpravy v sieti zákazníka. Spravidla si vo veľmi jednoduchom prípade nainštalujeme Zabbix priamo k sebe do jedného z dátových centier (našťastie máme dve z nich v kancelárii CROC na Volochaevskej). V zložitejšom prípade, ak napríklad používate vlastnú zabezpečenú sieť – na jeden zo strojov v dátovom centre zákazníka:

Zabbix sa dá použiť zložitejšie, napríklad má agentov, ktorí sú nainštalovaní na * nix a win uzly a zobrazujú monitorovanie systému, ako aj režim externej kontroly (s podporou protokolu SNMP). Ak však biznis potrebuje niečo podobné, tak buď už má vlastný monitoring, alebo sa zvolí funkčne bohatšie riešenie. Samozrejme, toto už nie je open source a stojí to peniaze, ale aj banálny presný inventár už znižuje náklady asi o tretinu.
Robíme to aj my, ale to je príbeh kolegov. Tu poslali niekoľko snímok obrazovky Infosim:


Som operátor avatara, takže vám poviem viac o mojej práci.
Ako vyzerá typický incident?
Pred nami sú obrazovky s nasledujúcim všeobecným stavom:
O tomto objekte pre nás Zabbix zhromažďuje pomerne veľa informácií: číslo šarže, sériové číslo, využitie CPU, popis zariadenia, dostupnosť rozhraní atď. Všetky potrebné informácie sú dostupné z tohto rozhrania.
Bežný incident sa zvyčajne začína tým, že zákazníkovi vypadne jeden z kanálov vedúcich napríklad do predajne (ktorých má 200-300 kusov po celej krajine). Maloobchod je teraz dobre rozvinutý, nie ako pred siedmimi rokmi, takže pokladňa bude fungovať aj naďalej - existujú dva kanály.
Dvíhame telefóny a telefonujeme minimálne trikrát: poskytovateľovi, elektrárni a ľuďom na mieste („Áno, nakladali sme sem armatúry, niekomu sa dotkol kábel... Aha, ten váš? No dobre, že našli sme to“).
Bez monitorovania by pred eskaláciou spravidla prešli hodiny alebo dni – nie vždy sa kontrolujú rovnaké záložné kanály. Hneď vieme a hneď odchádzame. Ak sú okrem pingov aj ďalšie informácie (napríklad model buginy železa), ihneď doplníme terénneho inžiniera potrebnými dielmi. Ďalej už na mieste.
Druhým najčastejším pravidelným hovorom je výpadok jedného z koncových zariadení pre užívateľov, napríklad DECT telefónu alebo Wi-Fi routera, ktorý distribuoval sieť do kancelárie. Tu sa dozvieme o probléme z monitorovania a takmer okamžite dostaneme hovor s podrobnosťami. Niekedy hovor nepridá nič nové („dvíham telefón, niečo nezvoní“), niekedy je veľmi užitočný („Zhodili sme to zo stola“). Je jasné, že v druhom prípade zjavne nejde o zalomenie riadku.
Zariadenia v Moskve sa odoberajú z našich horúcich rezervných skladov, máme ich niekoľko typov:

Zákazníci majú zvyčajne vlastné zásoby často zlyhávajúcich komponentov – kancelárske slúchadlá, napájacie zdroje, ventilátory atď. Ak potrebujete doručiť niečo, čo nie je na mieste, nie do Moskvy, zvyčajne ideme sami (pretože inštalácia). Mal som napríklad nočný výlet do Nižného Tagilu.
Ak má zákazník vlastný monitoring, môže nám nahrať dáta. Niekedy nasadíme Zabbix v režime hlasovania, len aby sme zabezpečili transparentnosť a kontrolu SLA (aj to je pre zákazníka bezplatné). Dodatočné senzory neinštalujeme (to robia kolegovia, ktorí zabezpečujú kontinuitu výrobných procesov), ale vieme sa na ne pripojiť, ak protokoly nie sú exotické.
Vo všeobecnosti sa nedotýkame infraštruktúry zákazníka, len ju podporujeme takú, aká je.
Zo skúsenosti môžem povedať, že posledných desať zákazníkov prešlo na externú podporu z dôvodu, že sme nákladovo veľmi predvídateľní. Prehľadné rozpočtovanie, dobrý manažment prípadov, správa o každej požiadavke, SLA, správy o zariadeniach, preventívna údržba. V ideálnom prípade sme samozrejme pre CIO zákazníka ako sú upratovačky - prídeme a urobíme, všetko je čisté, nerozptyľujeme.
Ďalšou vecou, ktorú stojí za zmienku, je, že v niektorých veľkých spoločnostiach sa inventarizácia stáva skutočným problémom a niekedy nás priťahuje iba jej vykonanie. Okrem toho robíme ukladanie konfigurácií a ich správu, čo je výhodné pri rôznych presunoch a prepojení. Ale opäť, v zložitých prípadoch to tiež nie som ja – máme špeciálne jedno, ktoré prepravuje dátové centrá.
A ešte jeden dôležitý bod: naše oddelenie sa nezaoberá kritickou infraštruktúrou. Všetko vo vnútri dátových centier a všetko, čo sa týka bankovníctva, poisťovníctva a operátorov, plus maloobchodné základné systémy – to je X-team. títo ľudia.
Viac praxe
Mnohé moderné zariadenia sú schopné poskytnúť množstvo servisných informácií. Napríklad sieťové tlačiarne dokážu veľmi jednoducho sledovať hladinu tonera v kazete. Môžete rátať s výmenným termínom vopred, plus mať 5-10% notifikáciu (ak zrazu kancelária začne zúrivo písať nie v štandardnom rozvrhu) - a hneď poslať enikey skôr, než začne učtárne panikáriť.Veľmi často nám odoberajú ročné štatistiky, ktoré robí ten istý monitorovací systém plus my. V prípade Zabbixu je to jednoduché plánovanie nákladov a pochopenie toho, čo sa kam podela a v prípade Infosim je to aj materiál na výpočet škálovania za rok, načítanie adminov a všelijaké iné veci. V štatistikách je spotreba energie - za posledný rok sa ho začali pýtať takmer všetci, zrejme preto, aby rozhádzali interné náklady medzi rezorty.
Niekedy sú dosiahnuté skutočné hrdinské záchrany. Takéto situácie sú veľmi zriedkavé, ale čo si pamätám tento rok, videli sme okolo 3:00, že teplota na spínači cisco stúpla na 55 stupňov. Vo vzdialenej serverovni boli "hlúpe" klimatizácie bez monitorovania a zlyhali. Okamžite sme zavolali chladiaceho technika (nie nášho) a zavolali do služby admina zákazníka. Spustil niekoľko nekritických služieb a udržal serverovňu pred tepelným výpadkom, kým neprišiel chlapík s mobilnou klimatizáciou, a potom boli opravené tie bežné.
Polycomy a iné drahé videokonferenčné zariadenia veľmi dobre monitorujú úroveň nabitia batérie pred konferenciami, čo je tiež dôležité.
Každý potrebuje monitorovanie a diagnostiku. Spravidla je to dlho a ťažko implementovateľné bez skúseností: systémy sú buď extrémne jednoduché a predkonfigurované, alebo veľkosti lietadlovej lode a s kopou štandardných správ. Zostrovať do súboru pre firmu, vymýšľať implementáciu ich úloh pre interné IT oddelenie a zobrazovať informácie, ktoré najviac potrebujú, plus udržiavať celú históriu aktuálnu, ak nie sú skúsenosti s implementáciou, je to hračka. Pri práci s monitorovacími systémami volíme zlatú strednú cestu medzi bezplatnými a špičkovými riešeniami – spravidla nie najobľúbenejších a „hrubších“ predajcov, ale jednoznačne riešiacich problém.
Raz došlo k dosť atypickému ošetreniu. Zákazník musel router odovzdať niektorej zo svojich oddelených divízií a presne podľa inventára. Smerovač mal modul s uvedeným sériovým číslom. Keď sa router začal pripravovať na cestu, ukázalo sa, že tento modul chýba. A nikto to nevie nájsť. Problém mierne zhoršuje skutočnosť, že inžinier, ktorý s touto pobočkou pracoval minulý rok, je už na dôchodku a odišiel bývať k vnúčatám do iného mesta. Kontaktovali nás a požiadali nás, aby sme sa pozreli. Našťastie hardvér poskytoval správy o sériových číslach a Infosim urobil inventúru, takže sme tento modul našli v infraštruktúre za pár minút a popísali topológiu. Utečenca vypátrali pomocou kábla - bol v inej serverovni v skrini. História hnutia ukázala, že sa tam dostal po zlyhaní podobného modulu.

Snímka z celovečerného filmu o Hottabychovi, presne vystihujúca vzťah obyvateľstva ku kamerám
Veľa incidentov s kamerou. Raz zlyhali 3 kamery naraz. Prerušenie kábla v jednej zo sekcií. Inštalatér vyfúkol novú do zvlnenia, dve z troch komôr sa zdvihli po sérii šamanizmu. A tretí nie je. Navyše vôbec nie je jasné, kde sa nachádza. Dvíham videostream - posledné zábery tesne pred pádom - 4 ráno, vychádzajú traja muži v šatkách na tvárach, dole niečo jasné, kamera sa veľmi trasie, padá.
Raz nastavíme kameru, ktorá by sa mala zamerať na „zajacov“ preliezajúcich plot. Počas jazdy sme rozmýšľali, ako označíme bod, kde by sa mal objaviť narušiteľ. Neprišlo mi to vhod - za 15 minút, čo sme tam boli, vstúpilo do objektu 30 ľudí iba v bode, ktorý sme potrebovali. Rovný stôl.
Ako som už uviedol vyššie, príbeh o zbúranej budove nie je vtip. Akonáhle zmizol odkaz na vybavenie. Na mieste - nie je tam žiadny pavilón, kde prechádzala meď. Pavilón bol zbúraný, kábel bol preč. Videli sme, že router je mŕtvy. Inštalátor prišiel, začal sa pozerať - a vzdialenosť medzi uzlami je niekoľko kilometrov. V súprave má tester Vipnet, štandard - zvonilo z jedného konektora, zvonilo z druhého - išiel hľadať. Zvyčajne je problém okamžite viditeľný.

Sledovanie kábla: toto je vlnitá optika, pokračovanie príbehu od samého začiatku príspevku o uzle. Tu bol nakoniec okrem úplne úžasnej inštalácie problém aj v tom, že sa kábel vzdialil od úchytov. Tu vyliezť všetky a rôzne, a uvoľniť kovové konštrukcie. Približne päťtisícový predstaviteľ proletariátu rozbil optiku.
V jednom zariadení boli všetky uzly vypnuté približne raz týždenne. A zároveň. Pomerne dlho sme hľadali vzor. Inštalátor našiel nasledovné:
- Problém nastáva vždy pri striedaní toho istého človeka.
- Od ostatných sa líši tým, že nosí veľmi ťažký kabát.
- Za vešiakom na šaty je namontovaný automatický stroj.
- Kryt stroja niekto zobral už dávno, ešte v praveku.
- Keď tento súdruh príde do zariadenia, zvesí svoje oblečenie a ona vypne stroje.
- Okamžite ich opäť zapne.
Zariadenie bolo vypnuté v jeden a ten istý čas v rovnakom čase v noci. Ukázalo sa, že miestni remeselníci sa pripojili k nášmu napájaniu, vytiahli predlžovačku a strčili tam rýchlovarnú kanvicu a elektrický sporák. Keď tieto zariadenia pracujú súčasne, celý pavilón je vyradený.
V jednej z predajní našej obrovskej krajiny so zatvorením smeny neustále padala celá sieť. Inštalatér videl, že všetka energia bola privedená do osvetľovacieho vedenia. Akonáhle sa v predajni vypne stropné osvetlenie haly (ktoré spotrebuje veľa energie), vypnú sa všetky sieťové zariadenia.
Stal sa prípad, že školník prerušil kábel lopatou.
Často vidíme len meď ležať s roztrhanou vlnou. Raz, medzi dvoma dielňami, miestni remeselníci jednoducho poslali krútenú dvojlinku bez akejkoľvek ochrany.
Preč od civilizácie sa zamestnanci často sťažujú, že sú vystavení „našim“ zariadeniam. Rozvádzače na niektorých vzdialených miestach môžu byť v rovnakej miestnosti ako osoba v službe. V súlade s tým sme niekoľkokrát narazili na škodlivé babky, ktoré ich na začiatku zmeny vypínali.
Ďalšie vzdialené mesto na optiku zavesil mop. Odlomili vlnu zo steny a začali ju používať ako upevňovacie prvky pre vybavenie.

V tomto prípade sú jednoznačne problémy s výživou.
Čo dokáže „veľký“ monitoring
Stručne porozprávam o možnostiach serióznejších systémov na príklade inštalácií Infosim. Existujú 4 riešenia spojené do jednej platformy:- Manažment porúch - kontrola porúch a korelácia udalostí.
- Riadenie výkonnosti.
- Inventár a automatické zisťovanie topológie.
- Správa konfigurácie.
Samostatne o inventári. Modul nielen zobrazuje zoznam, ale aj sám zostavuje topológiu (aspoň v 95% prípadov sa o to pokúsi a urobí to správne). Umožňuje vám tiež mať po ruke aktuálnu databázu použitého a nečinného IT vybavenia (sieť, serverové vybavenie atď.), aby ste mohli včas vymeniť zastarané vybavenie (EOS / EOL). Vo všeobecnosti je to vhodné pre veľké podniky, ale v malých podnikoch sa veľa z toho robí ručne.
Príklady prehľadov:
- Správy podľa typu operačného systému, firmvéru, modelov a výrobcov zariadení;
- Report o počte voľných portov na každom prepínači v sieti / podľa vybraného výrobcu / podľa modelu / podľa podsiete atď.;
- Správa o novo pridaných zariadeniach za určité obdobie;
- Upozornenie tlačiarne na nízku hladinu tonera;
- Hodnotenie vhodnosti komunikačného kanála pre premávku citlivú na oneskorenia a straty, aktívne a pasívne metódy;
- Sledovanie kvality a dostupnosti komunikačných kanálov (SLA) - generovanie správ o kvalite komunikačných kanálov v členení podľa telekomunikačných operátorov;
- Funkcia kontroly zlyhaní a korelácie udalostí je implementovaná prostredníctvom mechanizmu analýzy koreňových príčin (bez toho, aby administrátori museli písať pravidlá) a mechanizmu Alarm States Machine. Root-Cause Analysis je analýza hlavnej príčiny nehody na základe nasledujúcich postupov: 1. automatická detekcia a lokalizácia miesta poruchy; 2. zníženie počtu mimoriadnych udalostí na jeden kľúč; 3. identifikácia dôsledkov zlyhania – koho a čo ovplyvnilo zlyhanie.

Stablenet – Embedded Agent (SNEA) – počítač o niečo väčší ako balíček cigariet.
Inštalácia sa vykonáva v bankomatoch alebo vyhradených segmentoch siete, kde sa vyžaduje testovanie dostupnosti. S ich pomocou sa vykonáva záťažové testovanie.
Cloudové monitorovanie
Ďalším modelom inštalácie je SaaS v cloude. Vyrobené pre jedného globálneho zákazníka (spoločnosť s nepretržitým výrobným cyklom s geografiou distribúcie od Európy po Sibír).Desiatky zariadení vrátane tovární a skladov na hotové výrobky. Ak ich kanály klesli a ich podpora bola vykonaná zo strany zahraničných úradov, začalo sa oneskorenie dodávky, čo pozdĺž vlny viedlo k ďalším stratám. Všetky práce sa robili na požiadanie a vyšetrovaním incidentu sa strávilo veľa času.
Monitoring sme nastavili špeciálne pre nich, následne sme ho dokončili na niekoľkých lokalitách podľa špecifík ich smerovania a hardvéru. Toto všetko sa dialo v cloude CROC. Projekt dokončili a odovzdali veľmi rýchlo.
Výsledkom je:
- Vďaka čiastočnému presunu správy sieťovej infraštruktúry bolo možné optimalizovať minimálne na 50 %. Neprístupnosť zariadenia, zaťaženie kanála, prekročenie parametrov odporúčaných výrobcom: to všetko je opravené do 5-10 minút, diagnostikované a odstránené do hodiny.
- Zákazník pri prijímaní služby z cloudu premieňa kapitálové náklady na nasadenie svojho systému na monitorovanie siete na prevádzkové náklady za predplatné našej služby, ktorého sa môže kedykoľvek vzdať.
Výhodou cloudu je, že pri našom rozhodovaní stojíme akoby nad ich sieťou a môžeme sa na všetko, čo sa deje, pozerať objektívnejšie. V tom čase, keby sme boli vo vnútri siete, videli by sme obraz len po uzol zlyhania a čo sa deje za ním, by sme už nevedeli.
Pár posledných obrázkov
Toto je „ranná hádanka“:
A toto je poklad, ktorý sme našli:

Toto bolo v hrudi:

A nakoniec o najvtipnejšom výstupe. Raz som išiel do maloobchodu.
Stalo sa tam nasledovné: najprv začalo kvapkať zo strechy na falošný strop. Potom sa vo falošnom strope vytvorilo jazero, ktoré erodovalo a rozdrvilo jednu z dlaždíc. V dôsledku toho to všetko vytrysklo na elektrikára. Potom už presne neviem, čo sa stalo, ale niekde vo vedľajšej miestnosti došlo ku skratu a začal požiar. Najprv zafungovali práškové hasiace prístroje a potom prišli hasiči a všetko naplnili penou. Prišiel som po nich na demontáž. Musím povedať, že tsiska 2960 to po tomto všetkom dostala presne - mohol som vyzdvihnúť konfiguráciu a poslať zariadenie na opravu.
Ešte raz, počas spúšťania práškového systému, bol Tsiskovsky 3745 v jednej plechovke takmer úplne naplnený práškom. Všetky rozhrania boli plné - 2 x 48 portov. Muselo to byť zaradené na mieste. Spomenuli sme si na posledný prípad, rozhodli sme sa pokúsiť sa odstrániť konfigurácie „horúce“, vytriasť ich, vyčistiť, ako najlepšie vieme. Zapli sme ho – najprv prístroj povedal „pff“ a kýchol na nás veľkým prúdom prášku. A potom to zaburácalo a vstalo.
Monitor Ping EMCO. Bezplatný asistent správcu
Ak má vaša infraštruktúra až 5 hostiteľov virtualizácie, môžete použiť bezplatnú verziu.
Ping Monitor: Nástroj na monitorovanie stavu sieťového pripojenia (zadarmo pre 5 hostiteľov)
Info:
Spoľahlivý monitorovací nástroj na automatickú kontrolu pripojenia k sieti hostiteľov vykonaním príkazu ping.
wiki:
Ping je nástroj na testovanie pripojení v sieťach založených na TCP/IP, ako aj bežný názov pre samotnú požiadavku.
Pomocný program odosiela požiadavky (ICMP Echo-Request) protokolu ICMP na zadaný hostiteľ a zachytáva prichádzajúce odpovede (ICMP Echo-Reply). Čas medzi odoslaním požiadavky a prijatím odpovede (RTT, z anglického Round Trip Time) vám umožňuje určiť spiatočné oneskorenia (RTT) pozdĺž trasy a frekvenciu straty paketov, teda nepriamo určiť preťaženie na dátové kanály a sprostredkujúce zariadenia.
Program ping je jedným z hlavných diagnostických nástrojov v sieťach TCP / IP a je súčasťou dodávky všetkých moderných sieťových operačných systémov.
https://ru.wikipedia.org/wiki/Ping
Program odosielaním pravidelných požiadaviek ICMP monitoruje sieťové pripojenia a upozorní vás na zistené obnovenie / pokles kanálov. EMCO Ping Monitor poskytuje štatistické údaje o pripojení, vrátane doby prevádzkyschopnosti, prerušení služby, zlyhania pingu atď.


Podľa vzhľadu tejto optiky, prechádzajúcej lesom ku kolektoru, môžeme usúdiť, že inštalatér trochu nedodržal technológiu. Mount na fotografii tiež naznačuje, že ide pravdepodobne o námorníka - morský uzol.
Som v zdravotníckom tíme fyzickej siete, inými slovami technická podpora, ktorá je zodpovedná za to, aby kontrolky na smerovačoch blikali tak, ako majú. Máme pod krídlami rôzne veľké spoločnosti s infraštruktúrou po celej krajine. Nelezieme do ich biznisu, našou úlohou je zabezpečiť, aby sieť fungovala na fyzickej úrovni a premávka prebiehala tak, ako má.
Všeobecným zmyslom práce je neustále dotazovanie uzlov, odstraňovanie telemetrie, testovacie chody (napríklad kontrola nastavení na nájdenie zraniteľností), zabezpečenie zdravia, sledovanie aplikácií, návštevnosti. Niekedy zásoby a iné zvrátenosti.
Poviem vám o tom, ako je to organizované a pár príbehov z výletov.
Ako to zvyčajne býva
Náš tím sedí v kancelárii v Moskve a vykonáva sieťovú telemetriu. V skutočnosti sú to neustále pingy uzlov, ako aj prijímanie monitorovacích údajov, ak je hardvér inteligentný. Najčastejšou situáciou je, že ping neprejde niekoľkokrát za sebou. Napríklad v 80 % prípadov maloobchodného reťazca ide o výpadok elektriny, takže keď vidíme tento obrázok, robíme nasledovné:- Najprv zavoláme poskytovateľovi o nehodách
- Potom - do elektrárne o odstávke
- Potom sa snažíme nadviazať spojenie s niekým v zariadení (nie vždy je to možné, napr. o 2:00)
- A nakoniec, ak vyššie uvedené nepomohlo do 5-10 minút, odídeme alebo pošleme „avatara“ - zmluvného inžiniera, ktorý sedí niekde v Iževsku alebo Vladivostoku, ak je tam problém.
- S „avatarom“ udržiavame neustály kontakt a „vedieme“ ho infraštruktúrou – máme senzory a servisné manuály, on má kliešte.
- Potom nám inžinier pošle správu s fotografiou, čo to bolo.
Dialóg niekedy vyzerá takto:
- Takže medzi budovami číslo 4 a 5 sa stratilo spojenie. Skontrolujte router v piatej.
- Objednávka vrátane. Nie je tam žiadne spojenie.
- Dobre, choďte po kábli do štvrtej budovy, tam je ďalší uzol.
-... Oppa!
- Čo sa stalo?
- Tu bol zbúraný 4. dom.
- Čo??
- K správe prikladám fotografiu. Nemôžem obnoviť dom v SLA.
Ale častejšie sa ukáže, že nájde prestávku a obnoví kanál.
Približne 60% výjazdov je „v mlieku“, pretože buď je prerušené napájanie (lopatou, majstrom, votrelcami), alebo poskytovateľ nevie o jeho poruche, alebo je krátkodobý problém odstránený skôr, ako inštalatér prichádza. Sú však chvíle, keď sa o probléme dozvieme skôr ako používatelia a skôr ako IT služby zákazníka, a komunikujeme riešenie skôr, než si vôbec uvedomia, že sa niečo stalo. Najčastejšie k takýmto situáciám dochádza v noci, keď je aktivita v zákazníckych spoločnostiach nízka.
Kto to potrebuje a prečo
Každá veľká firma má spravidla svoje IT oddelenie, ktoré jasne rozumie špecifikám a úlohám. V stredných a veľkých podnikoch je práca „enikeevov“ a sieťových inžinierov často outsourcovaná. Je to len výhodné a pohodlné. Napríklad jeden maloobchodník má svojich vlastných skvelých IT ľudí, no ani zďaleka nenahrádzajú smerovače a sledujú káble.Čo robíme
- Pracujeme na žiadostiach - lístkoch a panikach.
- Robíme prevenciu.
- Riadime sa odporúčaniami predajcov hardvéru, napríklad čo sa týka podmienok údržby.
- Pripájame sa k monitorovaniu zákazníka a odstraňujeme z neho údaje, aby sme mohli v prípade incidentov cestovať.
Prvý spôsob – jednoduché kontroly – je len stroj, ktorý pingne všetky uzly v sieti a uistí sa, že reagujú správne. Takáto implementácia si nevyžaduje žiadne zmeny alebo minimálne kozmetické úpravy v sieti zákazníka. Spravidla si vo veľmi jednoduchom prípade nainštalujeme Zabbix priamo k sebe do jedného z dátových centier (našťastie máme dve z nich v kancelárii CROC na Volochaevskej). V zložitejšom prípade, ak napríklad používate vlastnú zabezpečenú sieť – na jeden zo strojov v dátovom centre zákazníka:
Zabbix sa dá použiť zložitejšie, napríklad má agentov, ktorí sú nainštalovaní na * nix a win uzly a zobrazujú monitorovanie systému, ako aj režim externej kontroly (s podporou protokolu SNMP). Ak však biznis potrebuje niečo podobné, tak buď už má vlastný monitoring, alebo sa zvolí funkčne bohatšie riešenie. Samozrejme, toto už nie je open source a stojí to peniaze, ale aj banálny presný inventár už znižuje náklady asi o tretinu.
Robíme to aj my, ale to je príbeh kolegov. Tu poslali niekoľko snímok obrazovky Infosim:
Som operátor avatara, takže vám poviem viac o mojej práci.
Ako vyzerá typický incident?
Pred nami sú obrazovky s nasledujúcim všeobecným stavom:
O tomto objekte pre nás Zabbix zhromažďuje pomerne veľa informácií: číslo šarže, sériové číslo, využitie CPU, popis zariadenia, dostupnosť rozhraní atď. Všetky potrebné informácie sú dostupné z tohto rozhrania.
Bežný incident sa zvyčajne začína tým, že zákazníkovi vypadne jeden z kanálov vedúcich napríklad do predajne (ktorých má 200-300 kusov po celej krajine). Maloobchod je teraz dobre rozvinutý, nie ako pred siedmimi rokmi, takže pokladňa bude fungovať aj naďalej - existujú dva kanály.
Dvíhame telefóny a telefonujeme minimálne trikrát: poskytovateľovi, elektrárni a ľuďom na mieste („Áno, nakladali sme sem armatúry, niekomu sa dotkol kábel... Aha, ten váš? No dobre, že našli sme to“).
Bez monitorovania by pred eskaláciou spravidla prešli hodiny alebo dni – nie vždy sa kontrolujú rovnaké záložné kanály. Hneď vieme a hneď odchádzame. Ak sú okrem pingov aj ďalšie informácie (napríklad model buginy železa), ihneď doplníme terénneho inžiniera potrebnými dielmi. Ďalej už na mieste.
Druhým najčastejším pravidelným hovorom je výpadok jedného z koncových zariadení pre užívateľov, napríklad DECT telefónu alebo Wi-Fi routera, ktorý distribuoval sieť do kancelárie. Tu sa dozvieme o probléme z monitorovania a takmer okamžite dostaneme hovor s podrobnosťami. Niekedy hovor nepridá nič nové („dvíham telefón, niečo nezvoní“), niekedy je veľmi užitočný („Zhodili sme to zo stola“). Je jasné, že v druhom prípade zjavne nejde o zalomenie riadku.
Zariadenia v Moskve sa odoberajú z našich horúcich rezervných skladov, máme ich niekoľko typov:
Zákazníci majú zvyčajne vlastné zásoby často zlyhávajúcich komponentov – kancelárske slúchadlá, napájacie zdroje, ventilátory atď. Ak potrebujete doručiť niečo, čo nie je na mieste, nie do Moskvy, zvyčajne ideme sami (pretože inštalácia). Mal som napríklad nočný výlet do Nižného Tagilu.
Ak má zákazník vlastný monitoring, môže nám nahrať dáta. Niekedy nasadíme Zabbix v režime hlasovania, len aby sme zabezpečili transparentnosť a kontrolu SLA (aj to je pre zákazníka bezplatné). Dodatočné senzory neinštalujeme (to robia kolegovia, ktorí zabezpečujú kontinuitu výrobných procesov), ale vieme sa na ne pripojiť, ak protokoly nie sú exotické.
Vo všeobecnosti sa nedotýkame infraštruktúry zákazníka, len ju podporujeme takú, aká je.
Zo skúsenosti môžem povedať, že posledných desať zákazníkov prešlo na externú podporu z dôvodu, že sme nákladovo veľmi predvídateľní. Prehľadné rozpočtovanie, dobrý manažment prípadov, správa o každej požiadavke, SLA, správy o zariadeniach, preventívna údržba. V ideálnom prípade sme samozrejme pre CIO zákazníka ako sú upratovačky - prídeme a urobíme, všetko je čisté, nerozptyľujeme.
Ďalšou vecou, ktorú stojí za zmienku, je, že v niektorých veľkých spoločnostiach sa inventarizácia stáva skutočným problémom a niekedy nás priťahuje iba jej vykonanie. Okrem toho robíme ukladanie konfigurácií a ich správu, čo je výhodné pri rôznych presunoch a prepojení. Ale opäť, v zložitých prípadoch to tiež nie som ja – máme špeciálny tím, ktorý prepravuje dátové centrá.
A ešte jeden dôležitý bod: naše oddelenie sa nezaoberá kritickou infraštruktúrou. Všetko vo vnútri dátových centier a všetko, čo sa týka bankovníctva, poisťovníctva a operátorov, plus maloobchodné základné systémy – to je X-team. Tu sú chalani.
Viac praxe
Mnohé moderné zariadenia sú schopné poskytnúť množstvo servisných informácií. Napríklad sieťové tlačiarne dokážu veľmi jednoducho sledovať hladinu tonera v kazete. Môžete rátať s výmenným termínom vopred, plus mať 5-10% notifikáciu (ak zrazu kancelária začne zúrivo písať nie v štandardnom rozvrhu) - a hneď poslať enikey skôr, než začne učtárne panikáriť.Veľmi často nám odoberajú ročné štatistiky, ktoré robí ten istý monitorovací systém plus my. V prípade Zabbixu je to jednoduché plánovanie nákladov a pochopenie toho, čo sa kam podela a v prípade Infosim je to aj materiál na výpočet škálovania za rok, načítanie adminov a všelijaké iné veci. V štatistikách je spotreba energie - za posledný rok sa ho začali pýtať takmer všetci, zrejme preto, aby rozhádzali interné náklady medzi rezorty.
Niekedy sú dosiahnuté skutočné hrdinské záchrany. Takéto situácie sú veľmi zriedkavé, ale čo si pamätám tento rok, videli sme okolo 3:00, že teplota na spínači cisco stúpla na 55 stupňov. Vo vzdialenej serverovni boli "hlúpe" klimatizácie bez monitorovania a zlyhali. Okamžite sme zavolali chladiaceho technika (nie nášho) a zavolali do služby admina zákazníka. Spustil niekoľko nekritických služieb a udržal serverovňu pred tepelným výpadkom, kým neprišiel chlapík s mobilnou klimatizáciou, a potom boli opravené tie bežné.
Polycomy a iné drahé videokonferenčné zariadenia veľmi dobre monitorujú úroveň nabitia batérie pred konferenciami, čo je tiež dôležité.
Každý potrebuje monitorovanie a diagnostiku. Spravidla je to dlho a ťažko implementovateľné bez skúseností: systémy sú buď extrémne jednoduché a predkonfigurované, alebo veľkosti lietadlovej lode a s kopou štandardných správ. Zostrovať do súboru pre firmu, vymýšľať implementáciu ich úloh pre interné IT oddelenie a zobrazovať informácie, ktoré najviac potrebujú, plus udržiavať celú históriu aktuálnu, ak nie sú skúsenosti s implementáciou, je to hračka. Pri práci s monitorovacími systémami volíme zlatú strednú cestu medzi bezplatnými a špičkovými riešeniami – spravidla nie najobľúbenejších a „hrubších“ predajcov, ale jednoznačne riešiacich problém.
Raz došlo k dosť atypickému ošetreniu. Zákazník musel router odovzdať niektorej zo svojich oddelených divízií a presne podľa inventára. Smerovač mal modul s uvedeným sériovým číslom. Keď sa router začal pripravovať na cestu, ukázalo sa, že tento modul chýba. A nikto to nevie nájsť. Problém mierne zhoršuje skutočnosť, že inžinier, ktorý s touto pobočkou pracoval minulý rok, je už na dôchodku a odišiel bývať k vnúčatám do iného mesta. Kontaktovali nás a požiadali nás, aby sme sa pozreli. Našťastie hardvér poskytoval správy o sériových číslach a Infosim urobil inventúru, takže sme tento modul našli v infraštruktúre za pár minút a popísali topológiu. Utečenca vypátrali pomocou kábla - bol v inej serverovni v skrini. História hnutia ukázala, že sa tam dostal po zlyhaní podobného modulu.
Snímka z celovečerného filmu o Hottabychovi, presne vystihujúca vzťah obyvateľstva ku kamerám
Veľa incidentov s kamerou. Raz zlyhali 3 kamery naraz. Prerušenie kábla v jednej zo sekcií. Inštalatér vyfúkol novú do zvlnenia, dve z troch komôr sa zdvihli po sérii šamanizmu. A tretí nie je. Navyše vôbec nie je jasné, kde sa nachádza. Dvíham videostream - posledné zábery tesne pred pádom - 4 ráno, vychádzajú traja muži v šatkách na tvárach, dole niečo jasné, kamera sa veľmi trasie, padá.
Raz nastavíme kameru, ktorá by sa mala zamerať na „zajacov“ preliezajúcich plot. Počas jazdy sme rozmýšľali, ako označíme bod, kde by sa mal objaviť narušiteľ. Neprišlo mi to vhod - za 15 minút, čo sme tam boli, vstúpilo do objektu 30 ľudí iba v bode, ktorý sme potrebovali. Rovný stôl.
Ako som už uviedol vyššie, príbeh o zbúranej budove nie je vtip. Akonáhle zmizol odkaz na vybavenie. Na mieste - nie je tam žiadny pavilón, kde prechádzala meď. Pavilón bol zbúraný, kábel bol preč. Videli sme, že router je mŕtvy. Inštalátor prišiel, začal sa pozerať - a vzdialenosť medzi uzlami je niekoľko kilometrov. V súprave má tester Vipnet, štandard - zvonilo z jedného konektora, zvonilo z druhého - išiel hľadať. Zvyčajne je problém okamžite viditeľný.
Sledovanie kábla: toto je vlnitá optika, pokračovanie príbehu od samého začiatku príspevku o uzle. Tu bol nakoniec okrem úplne úžasnej inštalácie problém aj v tom, že sa kábel vzdialil od úchytov. Tu vyliezť všetky a rôzne, a uvoľniť kovové konštrukcie. Približne päťtisícový predstaviteľ proletariátu rozbil optiku.
V jednom zariadení boli všetky uzly vypnuté približne raz týždenne. A zároveň. Pomerne dlho sme hľadali vzor. Inštalátor našiel nasledovné:
- Problém nastáva vždy pri striedaní toho istého človeka.
- Od ostatných sa líši tým, že nosí veľmi ťažký kabát.
- Za vešiakom na šaty je namontovaný automatický stroj.
- Kryt stroja niekto zobral už dávno, ešte v praveku.
- Keď tento súdruh príde do zariadenia, zvesí svoje oblečenie a ona vypne stroje.
- Okamžite ich opäť zapne.
Zariadenie bolo vypnuté v jeden a ten istý čas v rovnakom čase v noci. Ukázalo sa, že miestni remeselníci sa pripojili k nášmu napájaniu, vytiahli predlžovačku a strčili tam rýchlovarnú kanvicu a elektrický sporák. Keď tieto zariadenia pracujú súčasne, celý pavilón je vyradený.
V jednej z predajní našej obrovskej krajiny so zatvorením smeny neustále padala celá sieť. Inštalatér videl, že všetka energia bola privedená do osvetľovacieho vedenia. Akonáhle sa v predajni vypne stropné osvetlenie haly (ktoré spotrebuje veľa energie), vypnú sa všetky sieťové zariadenia.
Stal sa prípad, že školník prerušil kábel lopatou.
Často vidíme len meď ležať s roztrhanou vlnou. Raz, medzi dvoma dielňami, miestni remeselníci jednoducho poslali krútenú dvojlinku bez akejkoľvek ochrany.
Preč od civilizácie sa zamestnanci často sťažujú, že sú vystavení „našim“ zariadeniam. Rozvádzače na niektorých vzdialených miestach môžu byť v rovnakej miestnosti ako osoba v službe. V súlade s tým sme niekoľkokrát narazili na škodlivé babky, ktoré ich na začiatku zmeny vypínali.
Ďalšie vzdialené mesto na optiku zavesil mop. Odlomili vlnu zo steny a začali ju používať ako upevňovacie prvky pre vybavenie.
V tomto prípade sú jednoznačne problémy s výživou.
Čo dokáže „veľký“ monitoring
Stručne porozprávam o možnostiach serióznejších systémov na príklade inštalácií Infosim. Existujú 4 riešenia spojené do jednej platformy:- Manažment porúch - kontrola porúch a korelácia udalostí.
- Riadenie výkonnosti.
- Inventár a automatické zisťovanie topológie.
- Správa konfigurácie.
Samostatne o inventári. Modul nielen zobrazuje zoznam, ale aj sám zostavuje topológiu (aspoň v 95% prípadov sa o to pokúsi a urobí to správne). Umožňuje vám tiež mať po ruke aktuálnu databázu použitého a nečinného IT vybavenia (sieť, serverové vybavenie atď.), aby ste mohli včas vymeniť zastarané vybavenie (EOS / EOL). Vo všeobecnosti je to vhodné pre veľké podniky, ale v malých podnikoch sa veľa z toho robí ručne.
Príklady prehľadov:
- Správy podľa typu operačného systému, firmvéru, modelov a výrobcov zariadení;
- Report o počte voľných portov na každom prepínači v sieti / podľa vybraného výrobcu / podľa modelu / podľa podsiete atď.;
- Správa o novo pridaných zariadeniach za určité obdobie;
- Upozornenie tlačiarne na nízku hladinu tonera;
- Hodnotenie vhodnosti komunikačného kanála pre premávku citlivú na oneskorenia a straty, aktívne a pasívne metódy;
- Sledovanie kvality a dostupnosti komunikačných kanálov (SLA) - generovanie správ o kvalite komunikačných kanálov v členení podľa telekomunikačných operátorov;
- Funkcia kontroly zlyhaní a korelácie udalostí je implementovaná prostredníctvom mechanizmu analýzy koreňových príčin (bez toho, aby administrátori museli písať pravidlá) a mechanizmu Alarm States Machine. Root-Cause Analysis je analýza hlavnej príčiny nehody na základe nasledujúcich postupov: 1. automatická detekcia a lokalizácia miesta poruchy; 2. zníženie počtu mimoriadnych udalostí na jeden kľúč; 3. identifikácia dôsledkov zlyhania – koho a čo ovplyvnilo zlyhanie.
Stablenet – Embedded Agent (SNEA) – počítač o niečo väčší ako balíček cigariet.
Inštalácia sa vykonáva v bankomatoch alebo vyhradených segmentoch siete, kde sa vyžaduje testovanie dostupnosti. S ich pomocou sa vykonáva záťažové testovanie.
Cloudové monitorovanie
Ďalším modelom inštalácie je SaaS v cloude. Vyrobené pre jedného globálneho zákazníka (spoločnosť s nepretržitým výrobným cyklom s geografiou distribúcie od Európy po Sibír).Desiatky zariadení vrátane tovární a skladov na hotové výrobky. Ak ich kanály klesli a ich podpora bola vykonaná zo strany zahraničných úradov, začalo sa oneskorenie dodávky, čo pozdĺž vlny viedlo k ďalším stratám. Všetky práce sa robili na požiadanie a vyšetrovaním incidentu sa strávilo veľa času.
Monitoring sme nastavili špeciálne pre nich, následne sme ho dokončili na niekoľkých lokalitách podľa špecifík ich smerovania a hardvéru. Toto všetko sa dialo v cloude CROC. Projekt dokončili a odovzdali veľmi rýchlo.
Výsledkom je:
- Vďaka čiastočnému presunu správy sieťovej infraštruktúry bolo možné optimalizovať minimálne na 50 %. Neprístupnosť zariadenia, zaťaženie kanála, prekročenie parametrov odporúčaných výrobcom: to všetko je opravené do 5-10 minút, diagnostikované a odstránené do hodiny.
- Zákazník pri prijímaní služby z cloudu premieňa kapitálové náklady na nasadenie svojho systému na monitorovanie siete na prevádzkové náklady za predplatné našej služby, ktorého sa môže kedykoľvek vzdať.
Výhodou cloudu je, že pri našom rozhodovaní stojíme akoby nad ich sieťou a môžeme sa na všetko, čo sa deje, pozerať objektívnejšie. V tom čase, keby sme boli vo vnútri siete, videli by sme obraz len po uzol zlyhania a čo sa deje za ním, by sme už nevedeli.
Pár posledných obrázkov
Toto je „ranná hádanka“:
A toto je poklad, ktorý sme našli:
Toto bolo v hrudi:
A nakoniec o najvtipnejšom výstupe. Raz som išiel do maloobchodu.
Stalo sa tam nasledovné: najprv začalo kvapkať zo strechy na falošný strop. Potom sa vo falošnom strope vytvorilo jazero, ktoré erodovalo a rozdrvilo jednu z dlaždíc. V dôsledku toho to všetko vytrysklo na elektrikára. Potom už presne neviem, čo sa stalo, ale niekde vo vedľajšej miestnosti došlo ku skratu a začal požiar. Najprv zafungovali práškové hasiace prístroje a potom prišli hasiči a všetko naplnili penou. Prišiel som po nich na demontáž. Musím povedať, že tsiska 2960 to po tomto všetkom dostala presne - mohol som vyzdvihnúť konfiguráciu a poslať zariadenie na opravu.
Ešte raz, počas spúšťania práškového systému, bol Tsiskovsky 3745 v jednej plechovke takmer úplne naplnený práškom. Všetky rozhrania boli plné - 2 x 48 portov. Muselo to byť zaradené na mieste. Spomenuli sme si na posledný prípad, rozhodli sme sa pokúsiť sa odstrániť konfigurácie „horúce“, vytriasť ich, vyčistiť, ako najlepšie vieme. Zapli sme ho – najprv prístroj povedal „pff“ a kýchol na nás veľkým prúdom prášku. A potom to zaburácalo a vstalo.
žiadosť o echo
Požiadavka echo (ping) je diagnostický nástroj, ktorý sa používa na zistenie, či je konkrétny hostiteľ dostupný v sieti IP. Požiadavka na odozvu sa uskutočňuje pomocou protokolu ICMP (Internet Control Message Protocol). Tento protokol sa používa na odoslanie požiadavky na odozvu kontrolovanému hostiteľovi. Hostiteľ musí byť nakonfigurovaný na prijímanie paketov ICMP.
Vyšetrenie
žiadosťou o echo
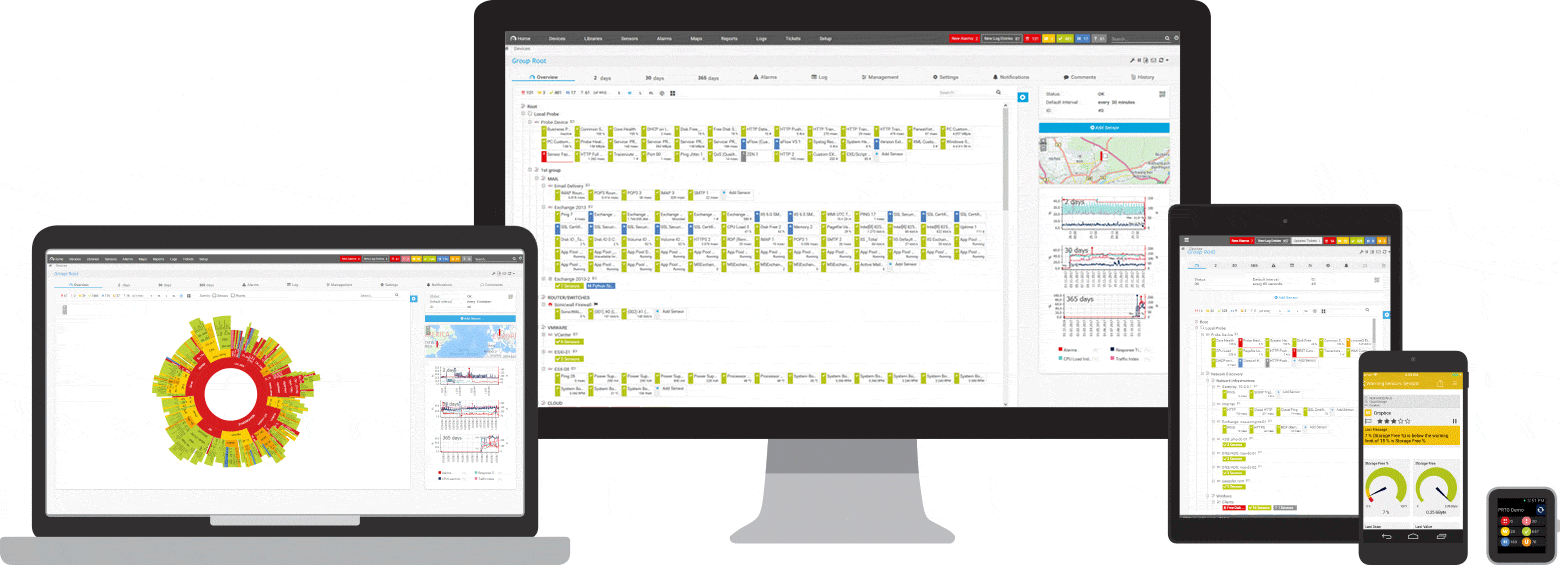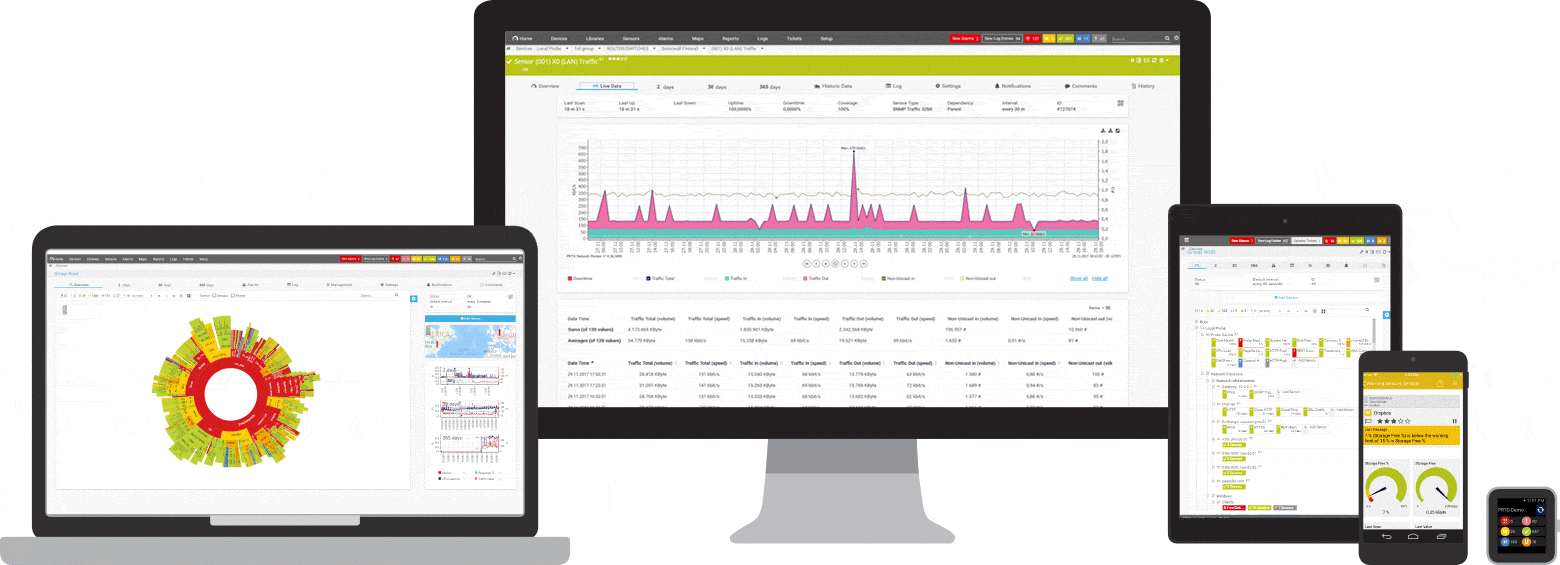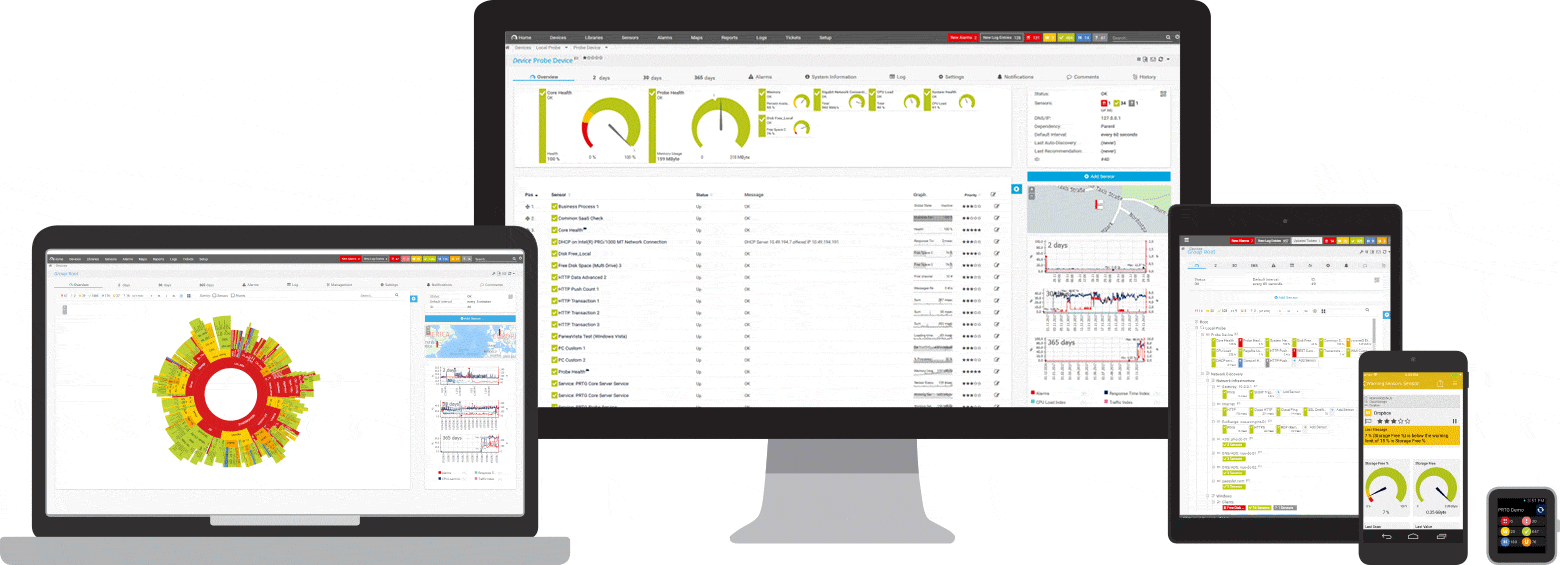
PRTG je ping a nástroj na monitorovanie siete pre Windows. Je kompatibilný so všetkými hlavnými systémami Windows, vrátane Windows Server 2012 R2 a Windows 10.
PRTG je výkonný nástroj pre celú sieť. V prípade serverov, smerovačov, prepínačov, uptime a cloudových pripojení PRTG sleduje všetko, aby ste sa mohli zbaviť administrácie. Senzor ping, ako aj senzory SNMP , NetFlow a paketové snímanie sa používajú na zhromažďovanie podrobných informácií o dostupnosti siete a pracovnej záťaži.
PRTG má prispôsobiteľný vstavaný poplašný systém, ktorý vás rýchlo upozorní na problémy. Senzor ping je nakonfigurovaný ako primárny senzor pre sieťové zariadenia. Ak tento senzor zlyhá, všetky ostatné senzory na zariadení sa prepnú do režimu spánku. To znamená, že namiesto prúdu varovných správ dostanete iba jedno upozornenie.
Na prístrojovej doske PRTG sa môže kedykoľvek zobraziť rýchly prehľad. Hneď uvidíte, či je všetko v poriadku. Prístrojová doska je prispôsobiteľná tak, aby vyhovovala vašim špecifickým potrebám. Mimo pracoviska, napríklad pri práci v serverovni, je prístup k PRTG možný prostredníctvom aplikácie pre smartfóny a nikdy nezmeškáte ani jednu udalosť.
Počiatočné monitorovanie sa konfiguruje ihneď počas inštalácie. Je to možné vďaka funkcii automatického zisťovania: PRTG testuje vaše súkromné IP adresy a automaticky vytvára senzory pre dostupné zariadenia. Pri prvom otvorení PRTG môžete okamžite skontrolovať dostupnosť vašej siete.
Program PRTG má transparentný licenčný model. PRTG môžete otestovať zadarmo. Senzor ping a funkcia alarmu sú tiež súčasťou bezplatnej verzie a majú neobmedzenú dobu používania. Ak vaša spoločnosť alebo sieť potrebuje viac funkcií, je ľahké aktualizovať licenciu.
Snímky obrazovky
Stručný úvod do PRTG: Ping Monitoring



Vaše pingové senzory v úplnom zobrazení
- aj na cestách
PRTG sa inštaluje za pár minút a je kompatibilný s väčšinou mobilných zariadení.
PRTG riadi týchto a mnohých ďalších výrobcov a aplikácií za vás
Tri PRTG senzory na monitorovanie pingu
Senzor
echo žiadosti
z oblaku
Cloud Ping Sensor využíva PRTG Cloud na meranie času potrebného na pingovanie vašej siete z rôznych miest po celom svete. Tento senzor vám umožňuje vidieť dostupnosť vašej siete v Ázii, Európe a Amerike. Tento ukazovateľ je veľmi dôležitý najmä pre medzinárodné spoločnosti. .
Zakúpením softvéru PRTG získate komplexnú bezplatnú podporu. Našou úlohou je vyriešiť vaše problémy čo najrýchlejšie! Špeciálne na to sme spolu s ďalšími materiálmi pripravili školiace videá a komplexnú príručku. Naším cieľom je odpovedať na všetky podporné lístky do 24 hodín (pracovné dni). V našej znalostnej báze nájdete odpovede na mnohé otázky. Napríklad vyhľadávací dopyt „ping monitoring“ vráti 700 výsledkov. Niekoľko príkladov:
„Potrebujem pingový senzor, ktorý bude zhromažďovať informácie iba o dostupnosti zariadenia bez toho, aby zmenil jeho stav. Je to možné?"
"Môžem vytvoriť inverzný snímač požiadavky na odozvu?"

"S PRTG sme oveľa pohodlnejšie, keď vieme, že naše systémy sú neustále monitorované."
Markus Puke, správca siete, klinika Schüchtermann (Nemecko)
- Plná verzia PRTG na 30 dní
- Po 30 dňoch - bezplatná verzia
- Pre rozšírenú verziu - komerčnú licenciu

| Softvér na monitorovanie siete – verzia 19.2.50.2842 (15. mája 2019) | |
|
Hosting |
K dispozícii je aj cloudová verzia (PRTG v cloude) |
Jazyky |
Angličtina, nemčina, ruština, španielčina, francúzština, portugalčina, holandčina, japončina a zjednodušená čínština |
Ceny |
Zadarmo až 100 senzorov (ceny) |
Komplexné monitorovanie |
Sieťové zariadenia, šírka pásma, servery, aplikácie, virtuálne prostredia, vzdialené systémy, internet vecí a ďalšie. |
Podporovaní poskytovatelia a aplikácie |
Monitorovanie siete a Ping s PRTG: Tri praktické prípadové štúdie
Na program PRTG sa spolieha 200 000 administrátorov po celom svete. Títo správcovia môžu pochádzať z rôznych odvetví, no všetci majú jedno spoločné – túžbu zabezpečiť a zlepšiť dostupnosť a výkon svojich sietí. Tri prípady použitia:

letisko v Zürichu
Letisko Zurich je najväčšie letisko vo Švajčiarsku, preto je obzvlášť dôležité, aby všetky jeho elektronické systémy fungovali hladko. Aby to bolo možné, IT oddelenie implementovalo softvér PRTG Network Monitor od Paessler AG. Tento nástroj s viac ako 4 500 senzormi zabezpečuje, že tím IT okamžite zistí a vyrieši problémy. V minulosti IT oddelenie využívalo rôzne monitorovacie programy. Vedenie však nakoniec dospelo k záveru, že softvér nie je vhodný na špecializované monitorovanie personálom prevádzky a údržby. Príklad použitia.

Univerzita Bauhaus, Weimar
IT systémy Univerzity Bauhaus vo Weimare využíva 5000 študentov a 400 zamestnancov. V minulosti sa na monitorovanie univerzitnej siete využívalo izolované riešenie na báze Nagios. Systém bol technicky zastaraný a nedokázal pokryť potreby IT infraštruktúry vzdelávacej inštitúcie. Modernizácia infraštruktúry by bola mimoriadne drahá. Namiesto toho sa univerzita obrátila na nové riešenia monitorovania siete. Vedúci IT chceli komplexný softvérový produkt, ktorý by bol užívateľsky prívetivý, ľahko sa inštaluje a nákladovo efektívny. Preto si vybrali PRTG. Príklad použitia.

Verejné služby mesta Frankenthal
O niečo viac ako 200 zamestnancov verejných služieb mesta Frankenthal je zodpovedných za dodávky elektriny, plynu a vody súkromným spotrebiteľom a organizáciám. Organizácia so všetkými svojimi budovami závisí aj od lokálne distribuovanej infraštruktúry, ktorá pozostáva z približne 80 serverov a 200 pripojených zariadení. Vedúci IT spoločnosti Frankenthal hľadali cenovo dostupný softvér, ktorý by vyhovoval ich špecifickým potrebám. Najprv IT nastavilo bezplatnú skúšobnú verziu PRTG. Verejné služby spoločnosti Frankenthal v súčasnosti používajú približne 1 500 senzorov na monitorovanie, okrem iného, verejných kúpalísk. Príklad použitia.

Praktické rady. Povedz mi, Greg, máš nejaké odporúčania na monitorovanie pingov?
„Pingback senzory sú pravdepodobne najdôležitejšími prvkami monitorovania siete. Musia byť správne nakonfigurované, najmä vzhľadom na vaše pripojenia. Ak napríklad monitorujete virtuálny stroj, je užitočné umiestniť pingový senzor na pripojenie k jeho hostiteľovi. Ak uzol zlyhá, nedostanete upozornenie pre každý virtuálny počítač, ktorý je k nemu pripojený. Okrem toho môžu byť senzory ping dobrým indikátorom toho, že sieťová cesta k hostiteľovi alebo internetu funguje správne, najmä v scenároch vysokej dostupnosti alebo zlyhania.“
Greg Campion, správca systému, PAESSLER AG